为什么我的 Claude Code 老是不按我说的做?如何写出让 Agent 准确执行的「共识协议」
- 先搞清楚 CLAUDE.md 是怎么被加载的
- 该写什么:那些 Agent 猜不到的东西
- 千万别写什么:Agent 自己能搞定的事
- 用 .claude/rules/ 做路径级精准控制
- @import 语法:CLAUDE.md 的模块化
- 验证策略:让 Agent 自证正确
- 多 Agent 场景下的共识问题
- 五个常见反模式(以及怎么修)
- 反模式 1:厨房水槽式(Kitchen Sink)
- 反模式 2:过度指定(Over-Specified)
- 反模式 3:反复纠正不记录(Correct-and-Forget)
- 反模式 4:信任-验证缺口(Trust-then-Verify Gap)
- 反模式 5:无限探索(Infinite Exploration)
- 一个可以直接抄的模板
- 常见问题
- 我的判断
概览: “CLAUDE.md 是你和 AI Agent 的共识协议。本文从加载机制、优先级、文件组织到常见反模式,手把手教你写出让 Claude Code 准确执行的项目指令,附完整配置示例和踩坑记录”
keywords: [“CLAUDE.md”, “Claude Code”, “AI 编程”, “Agent 指令”, “共识协议”, “prompt engineering”]
上周有人在群里问了一句:「为什么我的 Claude Code 老是不按我说的做?明明 CLAUDE.md 里写得很清楚了。」
我点开他的 CLAUDE.md 一看——482 行,从项目介绍到编码规范到 Git 提交格式到部署流程,事无巨细,恨不得把公司 wiki 搬进去。
问题出在哪?不是写多了,而是写的全是 Claude 自己能从代码里推断出来的东西。
真正需要写的——那些它猜不到的构建命令、那些违反默认习惯的项目规范——反而淹没在信息噪声里了。
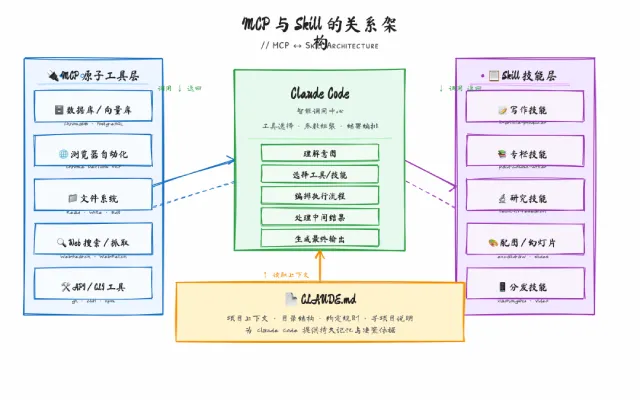
CLAUDE.md 不是文档,不是 README,不是给人看的。它是你和 AI Agent 之间的共识协议——就像分布式系统里节点之间约定好的通信规范,写对了,所有 Agent 按同一套规则执行;写错了,每次对话都在重复纠正同样的错误。
这篇文章是我自己折腾 CLAUDE.md 之后总结的实战指南。从加载机制讲到文件组织,从该写什么讲到千万别写什么,最后给一套可以直接抄的模板。
先搞清楚 CLAUDE.md 是怎么被加载的
写 CLAUDE.md 之前,必须理解它的加载机制。不然你不知道为什么某些指令生效了,某些没有。
Claude Code 启动时会从四个层级收集指令,优先级从高到低:
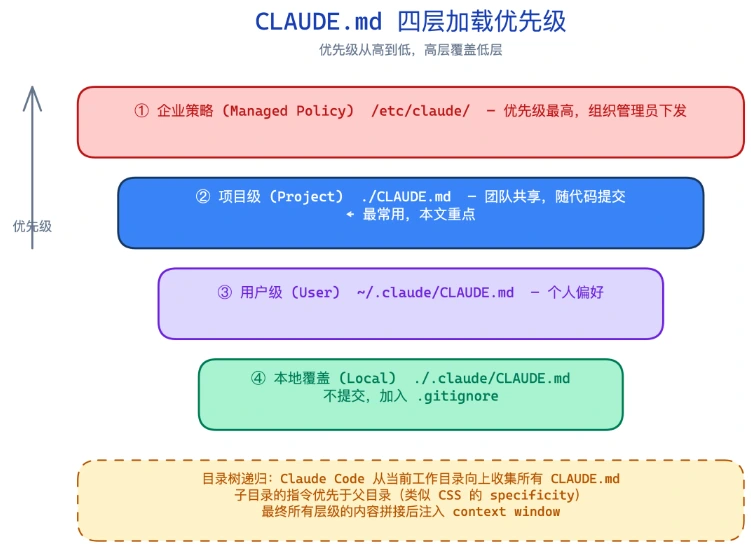
第一层:企业策略(Managed Policy)。这是组织管理员通过 /etc/claude/ 下发的全局策略,个人开发者一般用不到。优先级最高,会覆盖所有其他配置。
第二层:项目级(Project)。就是你项目根目录下的 CLAUDE.md 文件。这是最常用的,也是本文的重点。它随代码提交,团队成员共享同一份。
第三层:用户级(User)。放在 ~/.claude/CLAUDE.md,只对你自己生效。适合写个人偏好——比如你喜欢用中文回复、喜欢简短风格这类东西。
第四层:本地覆盖(Local Override)。放在项目根目录下的 .claude/CLAUDE.md(注意有个 .claude 目录),通常加入 .gitignore,不提交。适合写本地特有的环境变量路径、调试配置。
关键点来了:Claude Code 会沿目录树向上递归收集所有 CLAUDE.md。什么意思?如果你的项目结构是这样的:
my-monorepo/ ├── CLAUDE.md # 顶层:通用规范 ├── backend/ │ ├── CLAUDE.md # 后端子项目规范 │ └── src/ └── frontend/ ├── CLAUDE.md # 前端子项目规范 └── src/
当 Claude Code 在 backend/ 目录下工作时,它会同时加载 backend/CLAUDE.md 和 顶层的 CLAUDE.md,然后拼接在一起送入 context。这个机制和分布式系统里的配置层叠覆盖一模一样——全局配置打底,局部配置覆盖。
“踩坑记录:如果你在子目录和根目录的 CLAUDE.md 里写了矛盾的指令(比如根目录说「用 ESLint」,子目录说「用 Biome」),Claude 会优先听离当前工作目录更近的那个。但如果指令只是「不同」而不是「矛盾」,两者会合并生效。这个行为没有明确文档,我是踩坑发现的。
该写什么:那些 Agent 猜不到的东西
这是整篇文章最核心的部分。官方文档给了一个非常精准的判断标准:
写进 CLAUDE.md 的应该是 Claude 无法从代码本身推断出来的信息。
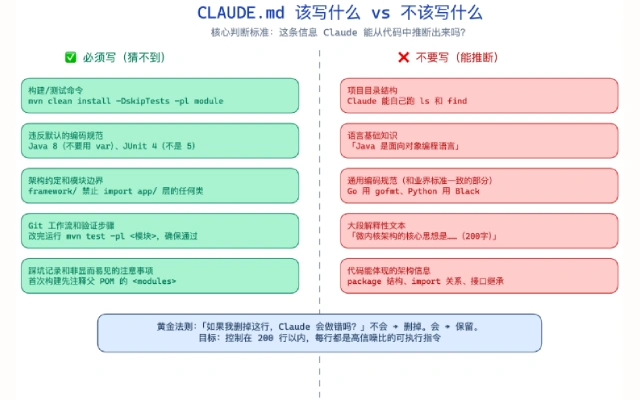
具体来说,有四类内容必须写:
1. 构建和测试命令
这是最高优先级。Claude 能读懂你的代码,但它猜不到你的构建系统怎么跑。
## 构建命令 - 构建整个项目:`mvn clean install -DskipTests` - 构建单个模块:`mvn clean install -DskipTests -pl dlm-framework/dlm-rule` - 运行测试:`mvn test -pl dlm-framework/dlm-rule` - 本地启动:`./scripts/dev-start.sh`(需要先启动 ZooKeeper 和 Redis) > 首次构建多模块项目时,先注释掉父 POM 的 <modules> 段,构建完成后恢复。
注意最后那行踩坑提示——这种信息 Claude 绝对猜不到,写进去能省掉每次手动解释的时间。
2. 违反默认习惯的编码规范
Claude 默认会按照业界最常见的规范写代码。如果你的项目有不同的约定,必须明确告知。
## 编码规范 - Java 版本:Java 8(不要使用 var、stream 的 toList()、records 等高版本特性) - 缩进:4 空格(不是 2 空格) - 测试框架:JUnit 4 + Mockito(不是 JUnit 5) - 日志:使用 @Slf4j 注解,不要手动创建 Logger 实例 - 异常处理:业务异常用 BizException,不要用 RuntimeException
这里的关键是「不是什么」比「是什么」更重要。Claude 可能默认用 JUnit 5 写测试——如果你不说「用 JUnit 4」,它就会按自己的判断来。
3. 架构约定和模块边界
Claude 能读懂单个文件,但它不一定理解你项目的整体架构意图。
## 架构约定 本项目采用微内核 + 插件架构: - `dlm-framework/` 是纯框架层,不允许包含任何业务逻辑 - `dlm-app/` 是业务服务层,每个服务遵循 api / service / web 三子模块模式 - 新增协议适配器放在 `dlm-protocol/`,实现 `IProtocolDispatcher` 接口 - RPC 调用通过 Dubbo,不要引入 Feign 或 RestTemplate 做服务间调用
4. 工作流程和提交规范
## Git 规范 - 提交信息格式:`<type>(<scope>): <subject>`,type 包括 feat/fix/refactor/docs/test - 不要用 --no-verify 跳过 pre-commit hook - PR 标题不超过 70 字符 - 每个 PR 只做一件事,不要混合功能开发和代码重构
千万别写什么:Agent 自己能搞定的事
写 CLAUDE.md 最常见的错误是信息过载。官方建议控制在 500 行以内——不是因为有硬性限制,而是因为每次对话启动时 CLAUDE.md 的内容都会被注入 context window,写太多等于每次都在浪费 token 预算。
以下内容不要写进 CLAUDE.md:
项目目录结构说明。 Claude 可以自己跑 ls 和 find,不需要你在 CLAUDE.md 里画 ASCII 目录树。
语言基础知识。 不需要写「Java 是一种面向对象的编程语言」或者「Spring Boot 是一个微服务框架」。Claude 知道。
通用编码规范。 如果你的规范和业界标准一致(比如 Go 用 gofmt、Python 用 Black),不需要重复写。只写不同的地方。
大段解释性文本。 CLAUDE.md 不是技术文档。Claude 需要的是可执行的指令,不是背景介绍。比较一下:
# ❌ 错误示范:解释性文本 我们的项目使用了微内核架构,这种架构的核心思想是将系统分为核心框架和插件模块。 核心框架提供基础的运行时环境和扩展点,而插件模块则通过实现这些扩展点来添加具体功能。 这种设计的好处是...(后面还有 200 字) # ✅ 正确示范:可执行指令 ## 架构规则 - framework/ 层不允许 import app/ 层的任何类 - 新插件必须实现 IPlugin 接口并注册到 PluginRegistry - 跨模块依赖通过 SPI 机制,不要直接 new
用 .claude/rules/ 做路径级精准控制
CLAUDE.md 是全局生效的。但有些规则只在特定文件上才有意义——比如「测试文件必须用 Given-When-Then 命名」这条规则,你不希望它在改 README 的时候也蹦出来。
.claude/rules/ 目录就是干这个的。每个 .md 文件可以通过 frontmatter 指定生效范围:
--- description: "测试文件编码规范" globs: ["**/test/**/*.java", "**/*Test.java"] --- - 测试方法命名:should*预期行为\_when*前置条件 - 每个测试方法只测一件事 - Mock 使用 @Mock 注解 + @InjectMocks,不要手动 new - 断言用 assertThat()(Hamcrest),不要用 assertEquals()
当 Claude 编辑匹配 glob 模式的文件时,这些规则会自动注入 context。编辑其他文件时,这些规则不存在。
这个机制的好处是精准投放,节省 token。你可以这样组织:
.claude/ └── rules/ ├── testing.md # globs: ["**/test/**"] ├── api-design.md # globs: ["**/controller/**", "**/api/**"] ├── database.md # globs: ["**/mapper/**", "**/repository/**"] └── frontend.md # globs: ["src/components/**/*.tsx"]
“踩坑记录:如果一个 rule 文件没有 globs 字段(或者 globs 为空),它会始终生效,等价于写在 CLAUDE.md 里。用这个特性可以把一些「总是需要但又不想塞进 CLAUDE.md」的规则外置。
@import 语法:CLAUDE.md 的模块化
当项目规模大到 CLAUDE.md 超过 200 行时,拆分是唯一的出路。@import 语法让你可以把 CLAUDE.md 拆成多个文件:
# CLAUDE.md ## 通用规范 @docs/coding-standards.md @docs/git-conventions.md ## 构建指南 @docs/build-guide.md ## 架构说明 @docs/architecture-rules.md
被引用的文件内容会在加载时展开,效果等同于直接写在 CLAUDE.md 里。
这个语法的价值在于关注点分离。编码规范变了,你只需要改 coding-standards.md,不需要在一个巨大的 CLAUDE.md 里翻找。团队中负责不同模块的人可以各自维护自己的规则文件。
但有一个需要注意的地方:import 的文件也计入总 token 消耗。拆分是为了可维护性,不是为了绕过长度限制。最终注入 context 的内容量是一样的。
验证策略:让 Agent 自证正确
写 CLAUDE.md 最容易忽略的一点是:光告诉 Agent「怎么做」不够,还要告诉它「做完之后怎么验证自己做对了」。
这就像分布式系统里的心跳检测——你不能只下发指令然后祈祷节点正确执行,你需要一个反馈机制。
## 验证清单 改完代码之后,按顺序执行以下检查: 1. `mvn compile -pl <修改的模块>` — 确保编译通过 2. `mvn test -pl <修改的模块>` — 确保测试通过 3. 检查是否有新增的编译警告 4. 如果修改了 API 接口,确保 Dubbo 的 api 模块也同步更新了 DTO
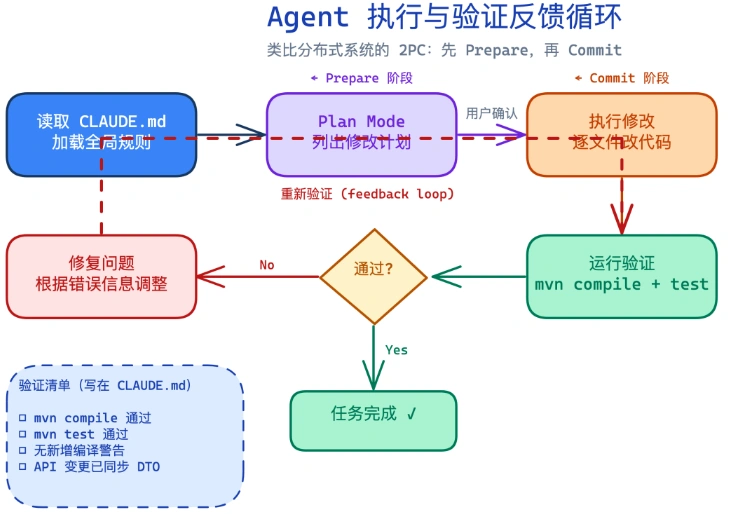
更高级的做法是在 CLAUDE.md 里引导 Claude 使用 Plan Mode:
## 复杂任务处理 对于涉及 3 个以上文件的修改: 1. 先进入 Plan Mode(/plan),列出所有要改的文件和改动点 2. 等我确认后再开始执行 3. 每改完一个文件就运行一次编译检查 4. 全部改完后跑完整测试套件
这相当于在共识协议里加了一个 两阶段提交(2PC):先 prepare(列计划),再 commit(执行修改)。如果 prepare 阶段发现计划不对,abort 的成本几乎为零。
多 Agent 场景下的共识问题
如果你用了 Claude Code 的 Sub-agent 或 Agent Teams 功能,CLAUDE.md 的作用就更关键了——它是所有 Agent 共享的唯一配置源。
每个被 spawn 出来的 Sub-agent 都会独立加载当前目录的 CLAUDE.md。这意味着:
好处:所有 Agent 天然遵守同一套规则,不需要额外的同步机制。这就是分布式系统里「配置中心」的作用。
风险:如果 CLAUDE.md 里的指令有歧义,不同 Agent 可能做出不同的解读——就像拜占庭将军问题里,同一条命令被不同节点解读出不同含义。
所以在多 Agent 场景下,CLAUDE.md 的指令必须做到无歧义、可执行、可验证:
# ❌ 有歧义的指令 - 代码要写得简洁 - 变量命名要有意义 - 适当添加注释 # ✅ 无歧义的指令 - 方法体不超过 30 行,超过就提取子方法 - 变量命名用 camelCase,布尔变量以 is/has/can 开头 - 只在「为什么这样做」不明显时添加注释,不要注释「做了什么」
如果你还配置了自定义 Sub-agent(放在 .claude/agents/ 目录),每个 agent 可以有自己的 system prompt 和工具白名单。但它们仍然会继承 CLAUDE.md 的全局规则。层级关系是:
CLAUDE.md(全局共识) └── .claude/agents/reviewer.md(agent 专属指令) └── 运行时 context(当前任务 + 对话历史)
“📊 [技术配图:架构图 – 多 Agent 配置继承关系]Excalidraw 文件:images/claude-md-writing-guide-consensus-protocol/multi-agent-config-inheritance.excalidraw 渲染后替换为 
五个常见反模式(以及怎么修)
Anthropic 官方文档里列出了几个高频踩坑模式,加上我自己的经验,总结如下:
反模式 1:厨房水槽式(Kitchen Sink)
症状:CLAUDE.md 超过 500 行,啥都往里塞。后果:context window 被大量低价值信息占用,真正重要的指令被稀释。修法:砍到 200 行以内。用「如果我删掉这行,Claude 会做错吗?」来判断每一行的去留。不会做错的就删。
反模式 2:过度指定(Over-Specified)
症状:把 Claude 能自己推断的东西也写进去。比如在一个 TypeScript 项目里写「使用 TypeScript 开发」。后果:噪声,而且容易和实际代码脱节——你 CLAUDE.md 里写的规范可能和代码库实际用的不一致。修法:只写差异项。问自己:「一个熟悉这个技术栈的高级工程师,看到代码后还需要被告知什么?」需要被告知的那些,才值得写。
反模式 3:反复纠正不记录(Correct-and-Forget)
症状:每次 Claude 犯同样的错误,你都在对话里纠正它,但从来不更新 CLAUDE.md。后果:下次新对话又犯。因为 CLAUDE.md 是跨对话持久化的,对话内的纠正不是。修法:**第二次纠正同一个问题时,立刻写进 CLAUDE.md 或 .claude/rules/**。这是一条铁律。
反模式 4:信任-验证缺口(Trust-then-Verify Gap)
症状:在 CLAUDE.md 里写了详细的指令,但没有写验证步骤。Claude 执行完了你才发现不对。后果:返工。尤其在多文件修改场景下,返工成本很高。修法:每个关键指令后面跟一条验证命令。参考上面「验证策略」章节。
反模式 5:无限探索(Infinite Exploration)
症状:没有告诉 Claude 项目的边界在哪里,它花大量 token 去读无关的文件。后果:token 浪费,执行慢,还可能被无关信息误导。修法:在 CLAUDE.md 里明确标注「不需要关注」的目录:
## 项目边界 - 忽略 `legacy/` 目录,这是已弃用的旧代码 - 忽略 `vendor/` 和 `node_modules/` - 只关注 `src/main/java/` 下的业务代码和 `src/test/` 下的测试代码
一个可以直接抄的模板
把上面所有实践汇总,一个 CLAUDE.md 的推荐结构长这样:
# CLAUDE.md ## 构建命令 [必须:构建、测试、启动命令,含前置条件和踩坑提示] ## 编码规范 [只写和默认不同的约定,越具体越好] ## 架构规则 [模块边界、依赖方向、禁止的做法] ## Git 规范 [提交格式、分支策略、PR 要求] ## 验证清单 [改完代码后的自动检查步骤] ## 项目边界 [哪些目录要关注,哪些要忽略]
配合 .claude/rules/ 做路径级细化:
.claude/ ├── CLAUDE.md # 本地覆盖(不提交) ├── agents/ │ └── reviewer.md # 代码审查专用 agent └── rules/ ├── testing.md # 测试文件专用规则 ├── api-design.md # API 层专用规则 └── database.md # 数据访问层专用规则
常见问题
Q:CLAUDE.md 和 AGENTS.md 是什么关系?
AGENTS.md 是行业通用的 agent 指令文件名,多家 AI 编程工具都支持。Claude Code 同时读取 CLAUDE.md 和 AGENTS.md,两者内容会合并。如果你的项目要兼容多个 AI 工具(比如同时用 Claude Code 和 Cursor),可以把通用规范放 AGENTS.md,Claude 专属配置放 CLAUDE.md。
Q:CLAUDE.md 写多长合适?
官方建议是保持精简,大致在 200 行以内。更重要的是信噪比——100 行全是高价值指令,比 500 行注水内容好得多。如果实在需要更多内容,用 @import 拆分或者用 .claude/rules/ 按路径分发。
Q:团队里每个人的习惯不一样怎么办?
项目级 CLAUDE.md 写团队共识(构建命令、架构规则、代码规范),个人偏好放 ~/.claude/CLAUDE.md(回复语言、交互风格)或者项目下的 .claude/CLAUDE.md(本地环境配置,加入 .gitignore 不提交)。
Q:怎么调试 CLAUDE.md 是否生效?
最直接的方法:在对话里问 Claude「你当前加载的 CLAUDE.md 内容是什么?」它会把已加载的指令列出来。如果某条规则没出现,检查文件路径和 glob 模式是否正确。
Q:CLAUDE.md 和 Claude Code 的 Memory 系统有什么区别?
CLAUDE.md 是声明式的静态配置,每次对话都加载,适合项目级规范。Memory(~/.claude/projects/<project>/memory/)是动态积累的上下文,跨对话持久化,适合记录用户偏好、项目进展这类随时间变化的信息。两者互补,不冲突。
我的判断
CLAUDE.md 本质上是一个人机共识协议的序列化格式。它的设计哲学和分布式系统的配置管理如出一辙:层叠覆盖、最小化传输、精确投放。
写好 CLAUDE.md 的核心原则只有一条:只写 Agent 猜不到的东西。其他的全删。
随着 Claude Code 的 Agent 能力越来越强——Sub-agents、Agent Teams、自定义 agents——CLAUDE.md 作为「共识层」的角色只会更重要。它不再只是一个配置文件,而是你和一个智能团队之间的沟通契约。合同写得好,团队才能高效运转。
下次你打开 CLAUDE.md 准备加点什么的时候,先停下来问自己一个问题:「如果我不写这行,Claude 会做错吗?」
如果答案是「不会」,那就别写。
文章来源微信公众号:码哥跳动
以上关于为什么我的 Claude Code 老是不按我说的做?如何写出让 Agent 准确执行的「共识协议」的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 为什么我的 Claude Code 老是不按我说的做?如何写出让 Agent 准确执行的「共识协议」