
独家教程:Python爬虫解密图形验证码的识别技巧
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还可能看到中文字符的验证码,这使得识别愈发困难。
后来 12306 验证码的出现使得行为验证码开始发展起来,用过 12306 的用户肯定多少为它的验证码头疼过。我们需要识别文字,点击与文字描述相符的图片,验证码完全正确,验证才能通过。现在这种交互式验证码越来越多,如极验滑动验证码需要滑动拼合滑块才可以完成验证,点触验证码需要完全点击正确结果才可以完成验证,另外还有滑动宫格验证码、计算题验证码等。
验证码变得越来越复杂,爬虫的工作也变得愈发艰难。有时候我们必须通过验证码的验证才可以访问页面。本章就专门针对验证码的识别做统一讲解。
本章涉及的验证码有普通图形验证码、极验滑动验证码、点触验证码、微博宫格验证码,这些验证码识别的方式和思路各有不同。了解这几个验证码的识别方式之后,我们可以举一反三,用类似的方法识别其他类型验证码。
我们首先识别最简单的一种验证码,即图形验证码。这种验证码最早出现,现在也很常见,一般由 4 位字母或者数字组成。例如,中国知网的注册页面有类似的验证码,链接为:点击这里,如图:
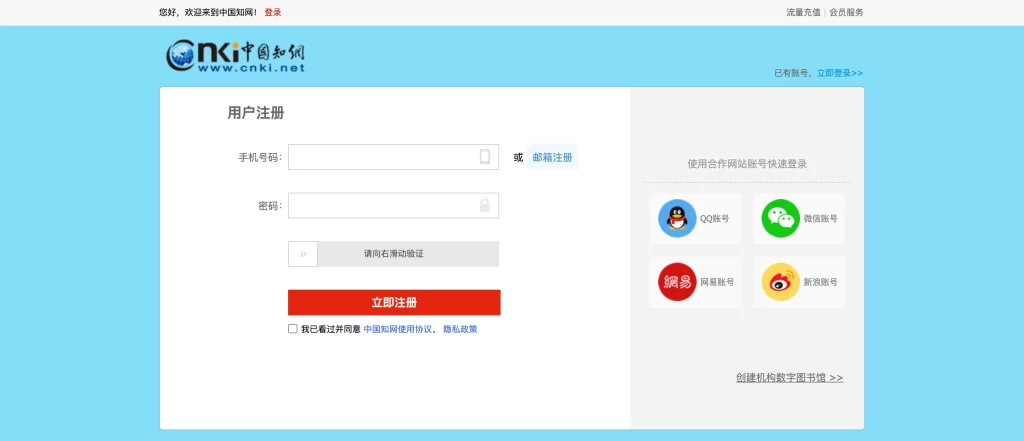
表单的最后一项就是图形验证码,我们必须完全正确输入图中的字符才可以完成注册。
1. 本节目标
以知网的验证码为例,讲解利用 OCR 技术识别图形验证码的方法。
2. 准备工作
识别图形验证码需要库 tesserocr。安装此库可以参考第 1 章的安装说明。
3. 获取验证码
为了便于实验,我们先将验证码的图片保存到本地。
打开开发者工具,找到验证码元素。验证码元素是一张图片,它的 src 属性是 CheckCode.aspx。我们直接打开这个链接 点击这里,就可以看到一个验证码,右键保存即可,将其命名为 code.jpg。
![]()
这样我们就可以得到一张验证码图片,以供测试识别使用。
4. 识别测试
接下来新建一个项目,将验证码图片放到项目根目录下,用 tesserocr 库识别该验证码,代码如下所示:
import tesserocr
from PIL import Image
image = Image.open('code.jpg')
result = tesserocr.image_to_text(image)
print(result)
在这里我们新建了一个 Image 对象,调用了 tesserocr 的 image_to_text() 方法。传入该 Image 对象即可完成识别,实现过程非常简单,结果如下所示:
UH4W
另外,tesserocr 还有一个更加简单的方法,这个方法可直接将图片文件转为字符串,代码如下所示:
import tesserocr
print(tesserocr.file_to_text('image.png'))
不过,此种方法的识别效果不如上一种方法好。
5. 验证码处理
接下来我们换一个验证码,将其命名为 code2.jpg。
![]()
重新用下面的代码来测试:
import tesserocr
from PIL import Image
image = Image.open('code2.jpg')
result = tesserocr.image_to_text(image)
print(result)
可以看到如下输出结果:
FFKT
这次识别和实际结果有偏差,这是因为验证码内的多余线条干扰了图片的识别。
对于这种情况,我们还需要做一下额外的处理,如转灰度、二值化等操作。
我们可以利用 Image 对象的 convert() 方法参数传入 L,即可将图片转化为灰度图像,代码如下所示:
image = image.convert('L')
image.show()
传入 1 即可将图片进行二值化处理,如下所示:
image = image.convert('1')
image.show()
我们还可以指定二值化的阈值。上面的方法采用的是默认阈值 127。不过我们不能直接转化原图,要将原图先转为灰度图像,然后再指定二值化阈值,代码如下所示:
image = image.convert('L')
threshold = 80
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
image.show()
在这里,变量 threshold 代表二值化阈值,阈值设置为 80。之后我们看看结果。
![]() 我们发现原来验证码中的线条已经去除,整个验证码变得黑白分明。这时重新识别验证码,代码如下所示:
我们发现原来验证码中的线条已经去除,整个验证码变得黑白分明。这时重新识别验证码,代码如下所示:
import tesserocr
from PIL import Image
image = Image.open('code2.jpg')
image = image.convert('L')
threshold = 127
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
result = tesserocr.image_to_text(image)
print(result)
即可发现运行结果变成如下所示:
PFRT
那么,针对一些有干扰的图片,我们做一些灰度和二值化处理,这会提高图片识别的正确率。
6. 结语
本节我们了解了利用 tesserocr 识别验证码的过程。我们可以直接用简单的图形验证码得到结果,也可以对验证码图片做预处理来。
以上关于独家教程:Python爬虫解密图形验证码的识别技巧的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 独家教程:Python爬虫解密图形验证码的识别技巧




