
Milvus 和 pgvector的区别是什么?
在 AI 应用开发,尤其是 RAG 场景的面试中,Milvus 和 pgvector 经常被放在一起比较。
很多人回答这个问题时,习惯用一句话概括:Milvus 更专业,pgvector 更轻量。这句话不能说错,但如果面试里只答到这里,基本很难体现真正的理解。
因为面试官更想听到的,其实是三件事:
它们的核心差异是什么、什么场景该选谁、放到真实项目里该怎么落地。
一、Milvus 和 pgvector 的核心区是什么?
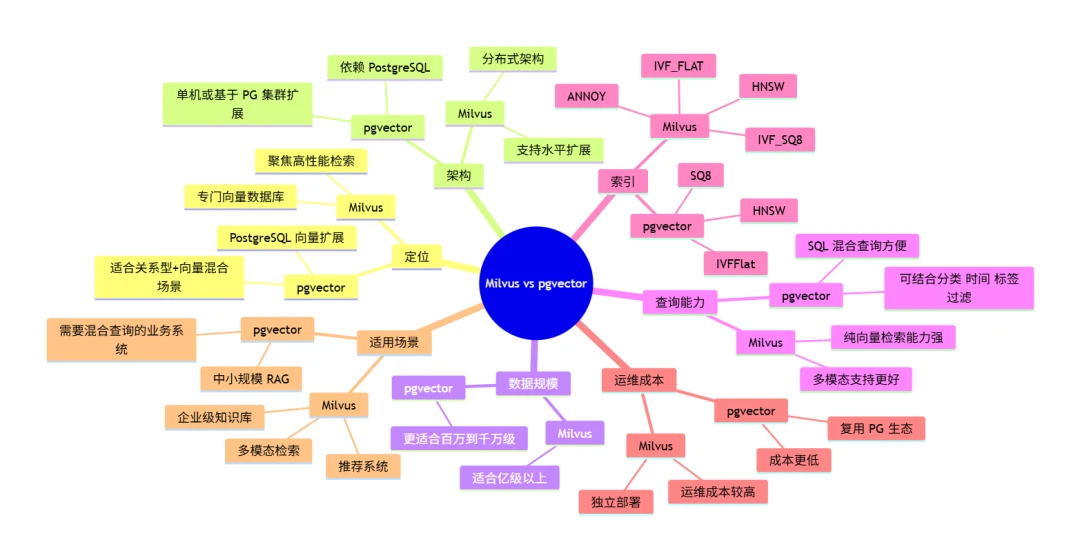
先说最本质的一点:两者的差异,来自于定位不同。
Milvus 是专门为向量检索设计的数据库,目标非常明确,就是把向量搜索这件事做到高性能、可扩展,适合大规模场景。
而 pgvector 本质上是 PostgreSQL 的向量扩展。它不是单独的一套向量数据库体系,而是让 PostgreSQL 具备向量检索能力。也就是说,它更强调的是关系型数据和向量数据的结合。
所以可以这样理解:
- Milvus:适合把向量检索能力做深;
- pgvector:适合把向量检索能力融入现有业务系统。
这也是为什么,很多人觉得它们像是在“对比性能”,但实际上更像是在“对比两种系统设计思路”。
二、为什么 Milvus 更适合大规模向量检索?
Milvus 的优势,首先来自它的架构。
它采用的是分布式设计,核心组件包括 Proxy、QueryNode、DataNode、IndexNode 等。简单来说:
- Proxy 负责接收请求和路由;
- QueryNode 负责查询计算;
- DataNode 负责数据写入和持久化;
- IndexNode 负责索引构建。
这种拆分带来的好处很直接:系统可以按角色做横向扩展。 当数据规模很大、查询并发很高时,Milvus 更容易撑住。
所以如果你的场景是企业知识库、大规模推荐系统、多模态检索,或者未来数据量会快速增长,Milvus 通常更有优势。因为它不是简单地“能存向量”,而是从一开始就是按海量向量检索来设计的。
三、那 pgvector 的优势到底在哪?
如果说 Milvus 的优势是“专”,那 pgvector 的优势就是“顺”。
它最大的价值,不在于向量检索性能一定比 Milvus 更强,而在于它和 PostgreSQL 生态融合得非常自然。
比如在很多 RAG 项目里,查询往往不是单纯做相似度搜索,而是要结合业务条件一起过滤:
- 只查某个分类下的文档;
- 只查最近三个月创建的内容;
- 按组织、权限、标签等字段先筛选;
- 再按向量相似度返回 Top K。
这类需求,本质上就是混合查询。而这恰恰是 pgvector 最顺手的地方,因为它可以直接依托 PostgreSQL 的 SQL、事务、普通索引和表结构设计来完成。
对于中小规模 RAG 来说,这种优势非常实际。因为很多时候,系统真正的难点不是“向量检索本身不够快”,而是“怎么把向量检索和现有业务数据体系整合好”。
四、面试里到底该怎么选?
这个问题几乎是必问的。
如果是面试回答,我会这样概括:
如果业务需要承载大规模向量检索,比如数据量很大、未来增长快、对性能和扩展要求高,那么优先考虑 Milvus。它更适合企业级知识库、推荐系统以及多模态检索场景。
如果业务是中小规模 RAG,同时又很依赖文档分类、时间范围、权限等关系型字段过滤,或者团队本身已经非常熟悉 PostgreSQL 的开发和运维,那么 pgvector 往往更合适。
说得更直白一点:
- 重性能、重扩展,选 Milvus;
- 重集成、重开发效率,选 pgvector。
这套逻辑通常比单纯说“一个专业一个轻量”更完整,也更像真实项目中的选型思路。
五、pgvector 的索引为什么也是高频考点?
如果面试官继续深挖,往往会问到:pgvector 支持哪些索引?RAG 场景中该怎么选?
常见的重点有两个:HNSW 和 IVFFlat。
HNSW
HNSW 的特点是查询速度快、精度高,通常比较适合实时问答这类对响应延迟敏感的场景。 但它的代价也很明显:索引构建更慢,而且更吃内存。
IVFFlat
IVFFlat 的优势是构建更快、资源开销更低,更适合数据量较大但资源有限的情况。 缺点是精度和查询效果通常不如 HNSW。
所以在面试里,一个比较实用的回答方式是:
- 数据量不大、追求查询速度,优先考虑 HNSW;
- 数据量更大、资源更紧张,可以考虑 IVFFlat。
这样的回答已经足够体现你对 pgvector 的实际理解。
六、从 Golang 工程落地看,两者差别也很明显
这一点很适合后端岗位面试时展开。
如果项目用 Milvus,通常会接入官方 Go SDK,通过 SDK 完成向量写入、索引管理和相似度检索。
这种方式更偏“专门系统”的接入模式。
而如果项目用 pgvector,很多时候你可以继续沿用 PostgreSQL 的 Go 驱动,比如 pgx,直接通过 SQL 来完成查询。
对于 Golang 工程师来说,这种方式门槛更低,也更符合日常开发习惯。
这也是为什么很多团队在做中小型 RAG 项目时,第一步往往会先从 pgvector 起步。因为它不是理论上最强,而是工程上最省事。
七、最后怎么总结,才像一个成熟的回答?
我觉得可以归纳成一句话:
Milvus 和 pgvector 没有绝对谁更好,关键看你的系统更需要“向量检索能力本身”,还是更需要“向量能力和业务系统的融合”。
Milvus 强在专业能力、扩展性和大规模检索; pgvector 强在 SQL 生态、混合查询和工程落地效率。
如果你能在面试里把这个逻辑讲清楚,再补上索引选择、Golang 接入方式和适用场景,基本就已经不是“背八股”的回答了,而是真正站在工程视角做判断。
以上关于Milvus 和 pgvector的区别是什么?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » Milvus 和 pgvector的区别是什么?