
英伟达发布全新小型模型 Nemotron-Nano-9B-V2:免费商用且性能卓越
在小型 AI 模型的热潮席卷而来之际,科技巨头英伟达也强势入局。此前,麻省理工学院和谷歌已先后推出可在智能手表、智能手机等设备上运行的小型 AI 模型,而英伟达紧随其后,发布了最新的小型语言模型——Nemotron-Nano-9B-V2。这款模型在多项基准测试中表现抢眼,尤其在特定测试里,更是达到了同类产品的顶尖水准。
Nemotron-Nano-9B-V2 的参数量为 90 亿,和那些仅有数百万参数的微型模型相比,它的规模确实大了不少,但相较于之前 120 亿参数的版本,已经有了显著缩减。更重要的是,它是专门针对单个英伟达 A10 GPU 进行优化的。英伟达 AI 模型后训练总监 Oleksii Kuchiaev 解释道,这样的调整是为了更好地适配 A10 这款在部署领域广受欢迎的 GPU。不仅如此,Nemotron-Nano-9B-V2 还是一款混合模型,它能够处理更大的批次任务,速度比同规模的 Transformer 模型快 6 倍,效率与推理能力可见一斑。
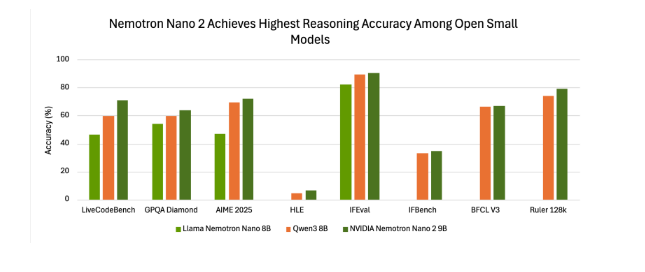
该模型支持多达九种语言,像中、英、德、法、日、韩等都包含在内,并且在指令跟踪和代码生成任务上展现出了出色的能力。目前,其预训练数据集和模型本身已在 Hugging Face 以及英伟达的模型目录中对外开放,方便开发者取用。
Nemotron-Nano-9B-V2 基于 Nemotron-H 系列打造,而该系列的一大特色就是融合了 Mamba 和 Transformer 两种架构。传统的 Transformer 模型虽然性能强大,但在处理长序列时,会耗费大量的内存和计算资源。Mamba 架构则引入了选择性状态空间模型(SSM),能够以线性复杂度处理长信息序列,在内存占用和计算开销方面更具优势。Nemotron-H 系列通过用线性状态空间层替代大部分注意力层,不仅让长上下文处理的吞吐量提升了 2-3 倍,还能保持较高的精度。
这款模型还有一个独特的创新点,就是内置了“推理”功能。这一功能允许用户在模型输出最终答案之前,让模型进行自我检查。用户只需通过简单的控制符,如/think 或/no_think,就能开启或关闭该功能。同时,模型还支持运行时“思考预算”管理,开发者可以限制用于内部推理的令牌数量,从而在准确性和延迟之间找到平衡。这对于客户支持、自主代理等对响应速度有较高要求的应用场景来说,无疑是一大福音。
在许可方面,英伟达依据其开放模型许可协议发布了 Nemotron-Nano-9B-V2,该协议对企业十分友好,且限制宽松。英伟达明确表示,企业可以自由地将该模型用于商业用途,无需支付任何费用或版税。
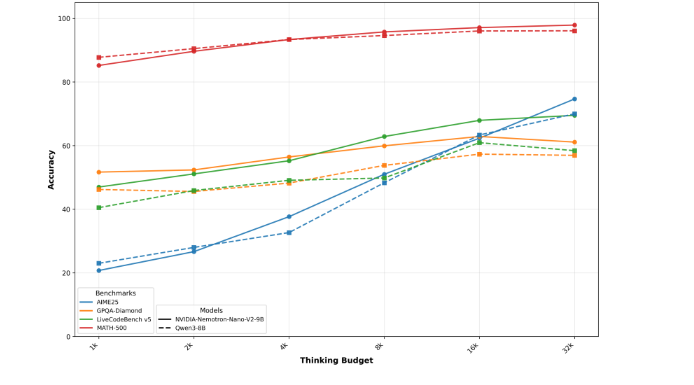
不过,协议也有一些核心要求,比如用户必须遵守模型内置的安全机制,在重新分发模型时进行归属标注,并且要遵守相关的法律法规。英伟达表示,该协议的目的是确保模型被负责任、合乎道德地使用,而非通过限制商业规模来盈利。这使得 Nemotron-Nano-9B-V2 成为了众多企业开发者的理想之选,尤其是那些希望在降低成本和延迟的同时,还能保持高精度的企业。
以上关于英伟达发布全新小型模型 Nemotron-Nano-9B-V2:免费商用且性能卓越的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 英伟达发布全新小型模型 Nemotron-Nano-9B-V2:免费商用且性能卓越







