如果有个产品是面向全球的,那它的日期管理是怎么设计的呢?时区如何处理?
前几天面试一个号称做过“高并发、分布式架构”的资深后端,聊到出海业务,我顺口问了一句:
“如果有个产品是面向全球的,那它的日期管理是怎么设计的呢?时区如何处理?”
结果这位仁兄极其自信、甚至带点不屑地回答:“这有啥难的?根据前端用户的 IP 拿到时区,后端 算一下不就行了?”
我心里直接好家伙。在国内做惯了单一时区的业务,真把全球化当成新手村了。如果真按他这么写,公司出海第一天,系统就能直接给你上演一出“时空错乱”的灾难。
一、 灾难复盘:服务器的谎言与“量子账单”
很多人总觉得:“时区不就是加减几个小时的事吗?”
我给你还原一个真实的生产级灾难现场。我们团队之前有个老弟就踩过这个雷:
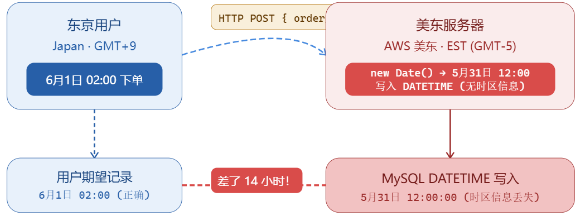
- 业务场景:东京用户在 6 月 1 日凌晨 02:00(日本时间,GMT+9)下了一笔订单。
- 致命代码:后端服务为了方便,直接用 获取当前时间并转化为明文存入 MySQL 的 字段。
- 点火爆炸:因为云服务器部署在美东机房,系统默认时区是 EST(GMT-5)。这行代码写入数据库的明文变成了 5 月 31 日 12:00。
- 灾难结果:纽约财务系统在导出 5 月 31 日的日账单时,莫名其妙把这笔属于 6 月 1 日的订单算进去了!东京系统对账时发现少了一笔钱,两边财务当天差点打起来,直接惊动了高管层。
为什么随手写一句 会成为全球化系统的致命毒药?
因为这些 API 严重依赖服务器本地的操作系统时区(OS Default Timezone)。JVM 启动时会读取主机的 。如果你们公司的 K8s 集群部署在全球不同的机房(比如 AWS 俄勒冈、阿里云法兰克福、腾讯云中国香港),只要哪台机器的底层时区没对齐,同一物理时刻,不同机器跑出来的明文时间就是完全错乱的!
面向全球的产品设计,核心原则只有八个字:统一存储,本地展示。
二、 终极架构:三层分工的“无时区”设计
为了彻底解决时区乱象,我们必须在整个技术栈的存储层、业务层、展示层拉起三道防线。
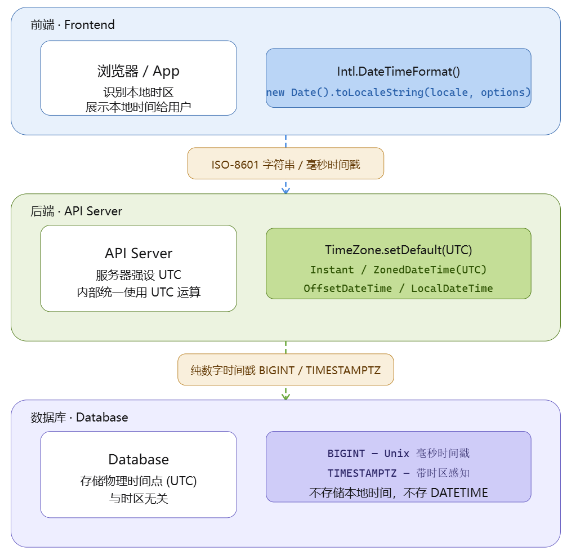
1. 存储层(Database):打破时区偏见
在数据库里,绝对不要存没有任何时区信息的明文日期(比如 MySQL 的 且服务器设为本地时区)。
- 黄金法则:存储 Unix 时间戳(Timestamp)。
时间戳是从 1970-01-01 00:00:00 UTC 开始计算的绝对毫秒数。它是一个纯数字,全世界任何一个角落、任何一个时区,在同一物理时刻,这个数字是绝对一致的。
- 生产规范:MySQL 中推荐使用 存储毫秒数;如果使用 PostgreSQL,推荐使用 ,它会自动帮你把写入时间转成 UTC 存储。
2. 业务逻辑层(Backend):绝对的 UTC 编排
- 规范一:所有生产服务器、Docker 镜像,系统时区必须统一强设为 UTC(GMT+0)。
- 规范二:Java 基础组件强行锁定 JVM 时区,防止读取宿主机时区污染:
public class GlobalApplication { public static void main(String[] args) { // 强行锁定 JVM 时区为 UTC TimeZone.setDefault(TimeZone.getTimeZone("UTC")); SpringApplication.run(GlobalApplication.class, args); } } - 规范三:驱动连接池(如 Druid/HikariCP)的 JDBC URL 必须显式指定时区,彻底掐断数据库时区协商环节的二义性。
jdbc:mysql://localhost:3306/db?serverTimezone=UTC&useSSL=false
- 规范四:代码中严禁使用依赖本地时区的旧 API(如 或 ),全面拥抱 Java 8 框架。
三、 手撕硬核代码:生产级多时区转换工具类
后端业务逻辑中,经常需要处理“用户在当地时间某天过期”、“计算用户当地时间明天零点”的业务。怎么写才稳妥?
Fox 给你们写一个标准的生产级时区处理工具类(基于 Java 8+)。消除了无谓的系统时区抓取,具备极高的并发性能与可测试性,建议直接收藏到你们的工具库里:
import java.time.*;
import java.time.format.DateTimeFormatter;
publicclass ZoneTimeKit {
/**
* 获取绝对时间戳(Instant),抹平服务器时区差异
*/
public static long getCurrentUtcEpochMilli() {
return Instant.now().toEpochMilli();
}
/**
* 将绝对时间戳转换为特定时区用户的“当地明文时间”
* @param epochMilli 绝对时间戳
* @param zoneIdStr IANA 时区 ID,如 "America/New_York"
*/
public static LocalDateTime convertToZoneLocal(long epochMilli, String zoneIdStr) {
Instant instant = Instant.ofEpochMilli(epochMilli);
ZoneId zoneId = ZoneId.of(zoneIdStr);
// ZonedDateTime 内部结合了 Instant 和 ZoneId
return ZonedDateTime.ofInstant(instant, zoneId).toLocalDateTime();
}
/**
* 基于指定的物理时间节点,计算特定时区用户当地时间“明天零点”对应的绝对时间戳
* 常用于计算精准的缓存(如 Redis)过期时间,规避高并发下隐式调用系统时钟的性能损耗
*
* @param baseEpochMilli 基准时间戳
* @param zoneIdStr IANA 时区 ID,如 "Asia/Tokyo"
*/
public static long getNextTargetZoneZeroHourMillis(long baseEpochMilli, String zoneIdStr) {
ZoneId zoneId = ZoneId.of(zoneIdStr);
Instant baseInstant = Instant.ofEpochMilli(baseEpochMilli);
// 将基准时间线转换到目标时区的墙上时间
ZonedDateTime nowInZone = ZonedDateTime.ofInstant(baseInstant, zoneId);
// 滚动到当地时间的明天零点
ZonedDateTime tomorrowZeroInZone = nowInZone.plusDays(1)
.withHour(0)
.withMinute(0)
.withSecond(0)
.withNano(0);
// 强转回绝对时间戳
return tomorrowZeroInZone.toInstant().toEpochMilli();
}
/**
* 解析标准的 ISO-8601 字符串(API 边界传输的标准格式)
*/
public static Instant parseIso8601(String isoString) {
// 输入示例: "2026-06-03T07:05:32Z" 或者 "2026-06-03T15:05:32+08:00"
return Instant.parse(isoString);
}
}
四、 避坑指南:剩下 20% 的架构级深坑
如果你以为统一用 UTC 就万事大吉了,那说明你还没见过真正复杂的全球化业务。以下两个场景,是各大厂架构师面试最爱问的“连环炮”。
1. 夏令时(DST)的“背叛”与 IANA 底层原理
美国和欧洲很多国家有夏令时。夏天把时钟拨快一小时,冬天拨回来。如果你在代码或数据库里硬编码:美国东部 = 小时。恭喜你,一到夏天,你算出来的业务时间就比人家实际慢了整整一小时!
Fox 敲黑板:数据库中绝对不能存储数字偏移量(如 -5 或 +8)。必须存储 IANA 时区标识符(Time Zone ID),例如 Europe/London 。
底层原理:为什么存字符串就能防夏令时?
因为时区规则是纯粹的政治产物。政客今天高兴可以宣布取消夏令时,明天高兴可以把时区从 强行改成 。
Java 底层和主流操作系统都内置了一个 TZDB(Time Zone Database)时区数据库。当年底政客们更改规则时,IANA 会发布更新补丁,JVM 也会随之更新。当你使用 时,JVM 会在运行时动态查询这个底层规则历史表,自动判定今天这个历史节点到底是 还是 。它保证了过去的时间按过去的规则算,未来的时间按最新的规则算。
2. 多时区批处理(全球用户的“自然日”怎么算?)
运营提了个高频需求:“全球用户在各自当地时间的 0:00 刷新每日签到奖励,并发放优惠券。”
你肯定不能只在 UTC 0 点跑一次定时任务,因为那时候中国是早上 8 点,美国是下午。如果你让几千万全球用户同时在某一时刻去扫全表,数据库当场就得瘫痪。
这时候必须采用分布式时区批处理(Time-zone Based Batching)架构:
- 第一步:数据冗余
用户注册或切换定位时,必须在用户表冗余其当前所在的 IANA 时区 ID,并在数据库建立索引:
ALTER TABLE user_profile ADD INDEX idx_timezone (timezone);
- 第二步:提高轮询精度,对齐“非整小时”时区
全球不仅有整小时时区,还有像印度(IST, UTC+5:30)、尼泊尔(UTC+5:45)这种奇葩的非整小时时区。因此,后端的分布式定时任务(如 XXL-JOB)绝不能每小时跑一次,必须设计成每 30 分钟(甚至 15 分钟)触发一次。
- 第三步:动态反推时区集群
任务每次执行时,获取当前的 UTC 时间,并动态反推出此时此刻,全球有哪些时区恰好跨入了当地时间的 00:00。例如:当分布式任务在 UTC 18:30 触发时,系统通过计算发现,此时 UTC+5:30 的地区(Asia/Kolkata,新德里)正好是当地时间的 24:00(即次日 00:00)。
- 第四步:精准捞取与分流削峰
分布式定时任务根据计算出来的时区列表,精准扫表:
-- 每次任务只捞取当前正好跨入零点的时区用户,绝不全表扫描
SELECT user_id FROM user_profile WHERE timezone IN ('Asia/Kolkata') AND status = 1;
捞出用户 ID 后,立即投递到消息队列(RocketMQ/Kafka),由微服务集群异步消费,发放奖励。
降维打击的效果显现了:这个设计把原本集中在某一物理时刻的全球大并发,均匀地稀释到了 24 小时的每一个半点和整点内。系统不仅实现了业务的本地化精准,还完美保护了核心数据库,极其优雅!
总结
全球化日期设计的终极密码就是:把复杂的时区转换推迟到离用户最近的那一刻(前端展示层)去解决。后端和存储层保持最纯粹、无歧义的绝对时间(UTC/时间戳)。
以上关于如果有个产品是面向全球的,那它的日期管理是怎么设计的呢?时区如何处理?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 如果有个产品是面向全球的,那它的日期管理是怎么设计的呢?时区如何处理?