
后端驱动全栈开发:如何实现Java校验规则秒传前端?
在很多团队里,前后端联调就像在玩“传声筒”游戏。后端 Java 同学改了一个 DTO 字段,或者加了个 @Max(100) 的约束,全靠口头通知或者 Swagger 文档。前端同学人肉同步 interface,手写校验逻辑。
这种靠“自觉”维持的同步,不仅低级,而且是典型的效率杀手。
今天聊聊我的观点:全栈开发,必须是“后端驱动”。 校验规则这种“真理”,必须从 Java 代码里长出来,直接“寄生”到前端。
为什么我推崇“后端驱动”?
道理很简单:数据库和业务逻辑都在后端,谁握着数据,谁就握着规则。
老兵们一定见过这种场面:
- Java 端改了手机号正则,前端没改。用户填完点击提交,前端校验通过,后端返回 400。用户一脸懵,前端在那查半天 Bug。
- 为了改一个字段名,你得在 DTO、Validator、TS Interface、Form Validation 里搜一圈。
我们要做的,是把 Java 的 DTO 直接“降维打击”到前端。
硬核实战:5 分钟实现“规则瞬移”
别误会,我不是让你推翻现有的 Axios 封装。我们要玩的是:只取 Schema 精华,不碰业务逻辑。
第一步:后端 Java 定义“真理”
在 Spring Boot 里,我们照常写代码,利用 JSR-380 注解。
public class UserRequest {
@NotBlank(message = "用户名必填")
@Size(min = 3, max = 20)
private String username;
@Email(message = "邮箱格式不对")
private String email;
}
第二步:定制你的“规则翻译官”
我们不需要 openapi-zod-client 生成那一坨臃肿的 API 调用代码。老开发追求的是极致干净。
创建一个模板 schema-only.hbs,告诉工具:我只要 Zod Schema,其他的别来沾边。
// schema-only.hbs
import { z } from "zod";
{{#each schemas}}
export const {{@key}} = {{this}};
export type {{@key}}Type = z.infer<typeof {{@key}}>;
{{/each}}
执行一行命令,直接从 Swagger JSON 生成纯净的 TS 校验文件:npx openapi-zod-client http://localhost:8080/v3/api-docs -o ./src/api/pure-schemas.ts --template schema-only.hbs
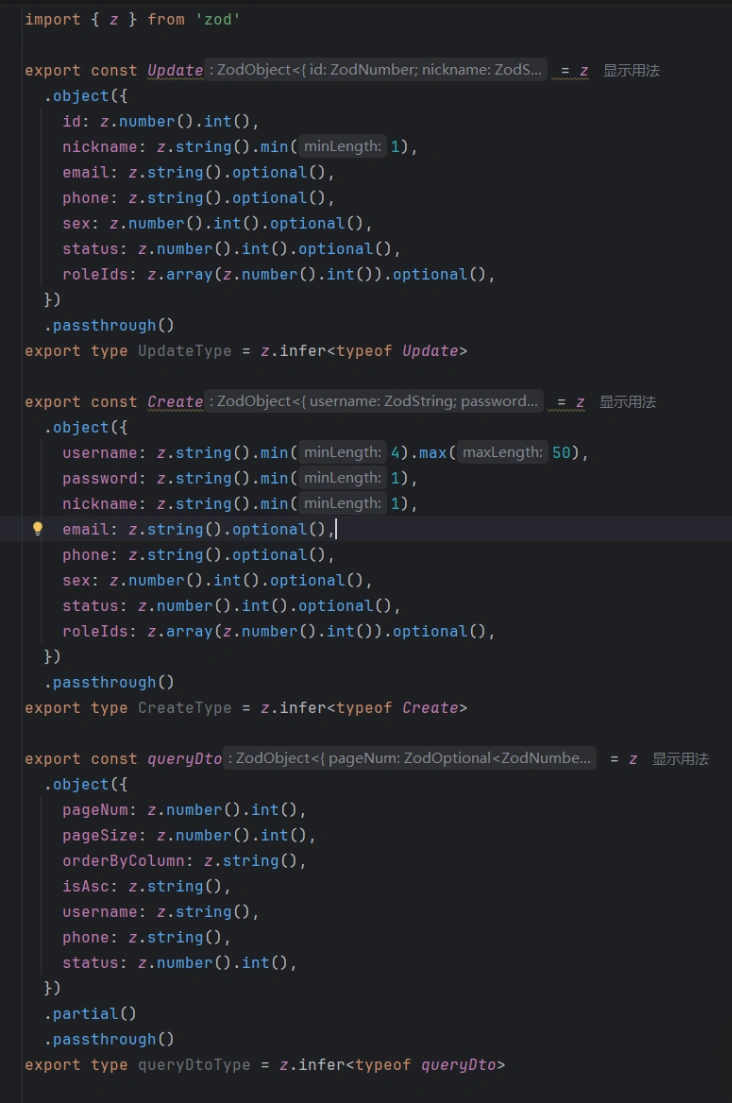
第三步:前端“白嫖”成果
现在,你的 Vue 3 项目里已经有了和 Java 完全同步的校验规则。
<script setup lang="ts">
import { UserRequest } from '@/api/pure-schemas';
import request from '@/utils/request'; // 你祖传的 axios 封装
const submit = async (data) => {
// 核心:直接用生成的 Schema 校验,逻辑跟后端 @Size 完全一致
const check = UserRequest.safeParse(data);
if (!check.success) {
console.error("前端直接拦截:", check.error.format());
return;
}
// 校验通过,稳稳地发请求
await request.post('/user/save', data);
};
</script>
结语
很多全栈喜欢把前后端分得清清楚楚,美其名曰“解耦”。但业务规则是不可能解耦的。
“后端驱动”的核心意义在于:
- 减少内耗: 后端改了代码,前端编译自动报错。这种“强约束”比开十次联调会都管用。
- 拒绝臃肿: 我们通过自定义模板,只拿走了最核心的规则,没有引入任何多余的库。
- 类型安全: 前端的 Type 是由 Schema 推导出来的,Schema 是由 Java 转换来的。这一条链路闭环,才是真正的全栈架构。
以上关于后端驱动全栈开发:如何实现Java校验规则秒传前端?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 后端驱动全栈开发:如何实现Java校验规则秒传前端?






