
GraphRAG:通过动态知识图谱提升人工智能

前言
在快速发展的人工智能领域,检索增强生成 (RAG) 已经成为提升大语言模型 (LLM) 事实准确性和相关性的重要技术。通过使 LLM 在生成响应之前能够从外部知识库中检索信息,RAG 减轻了诸如幻觉和过时信息等常见问题。
传统的 RAG 方法通常依赖于基于向量的相似性搜索,尽管这对广泛的检索是有效的,但在捕捉复杂数据中存在的复杂关系和上下文细微差别时有时会有所不足。这种局限性可能导致检索到碎片化的信息,阻碍 LLM 合成真正全面和上下文恰当的答案的能力。
进入 Graph RAG,这一突破性进展通过将知识图谱的权力直接整合到检索过程中,解决了这些挑战。与将信息视为独立块的常规 RAG 系统不同,Graph RAG 动态构建和利用知识图谱来理解实体和概念之间的相互关联。
这使得检索机制更加智能和精确,系统可以在数据中导航关系,不仅获取相关信息,还能获取丰富 LLM 理解的上下文。通过这样做,Graph RAG 确保检索到的知识不仅准确,而且具有深刻的上下文,从而显著提高响应质量并构建更强大的 AI 系统。
本文将深入探讨Graph RAG 的核心原则,探索其主要功能,通过代码示例展示其实用应用,并讨论它如何在构建更智能和可靠的 AI 应用中迈出重要一步。
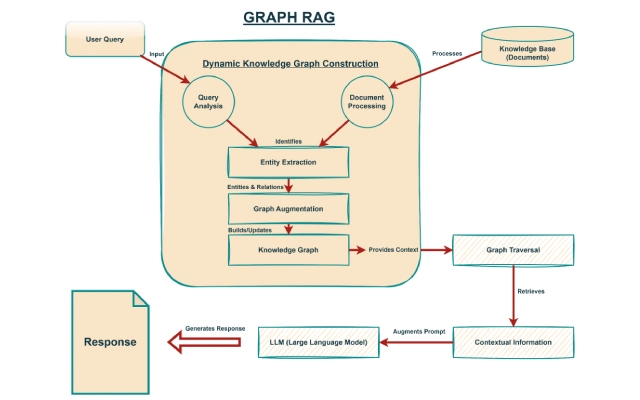
Graph RAG 的主要特点
Graph RAG 通过几个创新性功能使其在传统 RAG 架构中脱颖而出,这些功能共同提升了其检索能力和上下文理解能力。这些功能不仅仅是增加了功能,而是从根本上重塑了 LLMs 访问和利用信息的方式。
动态知识图谱构建
Graph RAG 最重要的功能之一是它能够在检索过程中动态构建知识图谱。
传统知识图谱通常是预先构建和静态的,需要大量的手动操作或复杂的 ETL(提取、转换、加载)管道来维护和更新。相比之下,Graph RAG 根据输入查询和初始检索结果识别的实体和关系,在实时构建或扩展图。
这种动态构建确保知识图谱始终与用户的查询即时上下文相关,避免管理庞大、全面的图谱的开销。这种动态特性使系统能够适应新信息和不断变化的上下文,而无需不断重新索引或重建图谱。
例如,如果一个查询提到一个新发现的科学概念,Graph RAG 可以将这个概念纳入其临时知识图谱中,并与现有的相关实体链接起来,从而提供最新和相关的信息。
智能实体链接
动态图构建的核心在于智能实体链接。
在信息处理过程中,Graph RAG 识别关键实体(例如,人、组织、地点、概念)并建立它们之间的关系。这超越了简单的关键词匹配;它涉及理解不同信息之间的语义联系。
例如,如果一个文档提到“GPT-4”,另一个文档提到“OpenAI”,系统可以通过“开发”关系将这些实体连接起来。这个连接过程是至关重要的,因为它允许 RAG 系统在图中导航并检索不仅直接的查询答案,还能提供更丰富上下文的相关信息。
这对实体高度互联的领域特别有益,例如医学研究、法律文件或财务报告。通过链接相关的实体,Graph RAG 确保了更全面和互联的检索,增强了 LLM 提供信息的深度和广度。
基于图遍历的上下文决策
与基于嵌入空间中语义相似性的向量搜索不同,Graph RAG 利用知识图谱中的显式关系进行上下文决策。
当提出一个查询时,系统不仅仅提取孤立的文档。它执行图遍历,沿着节点之间的路径来识别最相关和上下文最合适的的信息。
这意味着该系统可以回答复杂的、多跳的问题,这些问题是需要连接不相关的信息的。
例如,要回答“DeepMind 的首席科学家主要研究哪些领域?”这个问题,传统的 RAG 可能难以将 “DeepMind” 与它的 “首席科学家” 以及他们的 “研究领域” 联系起来,如果这些信息分散在不同的文档中。然而,Graph RAG 可以在图内直接导航这些关系,确保检索到的信息不仅准确,而且在更广泛的的知识网络中具有深度的上下文关联。
这种能力显著提高了系统处理复杂查询和提供更连贯、逻辑结构更完整的响应的能力。
用于精确检索的置信分数利用
为了进一步优化检索过程并防止包含无关或低质量的信息,Graph RAG 利用了从知识图谱中得出的置信度分数。
这些分数可以基于各种因素,例如实体之间关系的强度、信息的最新性或信息来源的感知可靠性。通过分配置信分数,该框架可以智能地决定何时以及如何检索外部知识。
该机制起到过滤器的作用,帮助优先处理高质量的相关信息,同时尽量减少噪音的添加。
例如,如果某个关系的置信度得分较低,系统可能会选择不沿着该路径扩展检索,从而避免引入可能具有误导性或未经验证的数据。
这种有选择性的扩展确保 LLM 收到紧凑且高度相关的事实集,通过为每个查询维护一个专注且相关的知识图谱,提高效率和响应准确性。
Graph RAG 的工作原理:分步解析
在学习之前理解 Graph RAG 的理论基础是必要的,但其真正的用途在于其实际应用。
本节将逐步介绍 Graph RAG 系统典型的流程,通过概念性的代码示例来说明每个阶段,以提供其操作机制的更清晰的图景。
虽然具体的实现可能会因所选择的图数据库、LLM 和具体使用案例而有所不同,但核心原则保持一致。
步骤 1:查询分析和初步实体提取
当用户提交查询时,过程就开始了。
Graph RAG 系统的第一步是分析这个查询,以识别关键实体和潜在关系。这通常涉及自然语言处理 (NLP)技术,例如命名实体识别 (NER)和依赖解析。
代码示例(Python):
import spacy
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import networkx as nx
# 加载 spaCy
nlp = spacy.load("en_core_web_sm")
# Step 1: 提取实体
def extract_entities(query):
doc = nlp(query)
return [(ent.text.strip(), ent.label_) for ent in doc.ents]
query = "Who is the CEO of Google and what is their net worth?"
extracted_entities = extract_entities(query)
print(f"🧠 Extracted Entities: {extracted_entities}"
效果:
![]()
步骤 2:初步检索和候选文档识别
实体被提取了,系统将从大量的文档语料库中进行初步检索。
这可以通过传统的向量搜索或关键词匹配来完成。这里的目标是识别出一组与查询潜在相关的候选文档。
代码示例(Python – 简化的向量搜索):
# Step 2: 检索候选文档
corpus = [
"Sundar Pichai is the CEO of Google.",
"Google is a multinational technology company.",
"The net worth of many tech CEOs is in the billions.",
"Larry Page and Sergey Brin founded Google."
]
vectorizer = TfidfVectorizer()
corpus_embeddings = vectorizer.fit_transform(corpus)
def retrieve_candidate_documents(query, corpus, vectorizer, corpus_embeddings, top_k=2):
query_embedding = vectorizer.transform([query])
similarities = cosine_similarity(query_embedding, corpus_embeddings).flatten()
top_indices = similarities.argsort()[-top_k:][::-1]
return [corpus[i] for i in top_indices]
candidate_docs = retrieve_candidate_documents(query, corpus, vectorizer, corpus_embeddings)
print(f"📄 Candidate Documents: {candidate_docs}")
结果:

步骤 3: 动态知识图谱的构建与增强
这是 Graph RAG 的核心。
从查询和候选文档的内容中提取的实体被用来动态地构建或扩展一个知识图谱。这包括在文本中识别新的实体和关系,并将它们作为图中的节点和边添加。如果已经存在一个基础知识图谱,这一步将扩展它;否则,它将为当前查询上下文从头开始构建一个新的图。
代码示例(Python – 使用 NetworkX 进行图表示):
# Step 3: 构建或扩充图谱
def build_or_augment_graph(graph, entities, documents):
for entity, entity_type in entities:
graph.add_node(entity, type=entity_type)
for doc in documents:
doc_nlp = nlp(doc)
person = None
org = None
for ent in doc_nlp.ents:
if ent.label_ == "PERSON":
person = ent.text.strip().strip(".")
elif ent.label_ == "ORG":
org = ent.text.strip().strip(".")
if person and org and "CEO" in doc:
graph.add_node(person, type="PERSON")
graph.add_node(org, type="ORG")
graph.add_edge(person, org, relation="CEO_of")
return graph
# 创建并填充图
knowledge_graph = nx.Graph()
knowledge_graph = build_or_augment_graph(knowledge_graph, extracted_entities, candidate_docs)
print("🧩 Graph Nodes:", knowledge_graph.nodes(data=True))
print("🔗 Graph Edges:", knowledge_graph.edges(data=True))
结果:

步骤 4:图遍历和上下文信息检索
有了动态知识图谱,系统从查询实体开始进行图遍历。它探索关系(边)和相关实体(节点),以检索上下文相关的信息。
这一步是 Graph RAG 中的“图”真正闪耀的地方,允许进行多跳推理并发现隐含的联系。
代码示例(Python – 图遍历):
# Step 4: 图遍历
def traverse_graph_for_context(graph, start_entity, depth=2):
contextual_info = set()
visited = set()
queue = [(start_entity, 0)]
while queue:
current_node, current_depth = queue.pop(0)
if current_node in visited or current_depth > depth:
continue
visited.add(current_node)
contextual_info.add(current_node)
for neighbor in graph.neighbors(current_node):
edge_data = graph.get_edge_data(current_node, neighbor)
if edge_data:
relation = edge_data.get("relation", "unknown")
contextual_info.add(f"{current_node} {relation} {neighbor}")
queue.append((neighbor, current_depth + 1))
return list(contextual_info)
context = traverse_graph_for_context(knowledge_graph, "Google")
print(f"🔍 Contextual Information from Graph: {context}")
结果:
![]()
步骤 5:置信度分数引导扩展(可选但推荐)
正如在功能中提到的,置信度分数 可以用于指导图的遍历。
这确保了检索到的信息扩展是受控的,并避免引入无关或低质量的数据。这可以通过为边或节点分配分数并优先考虑高分路径来整合到步骤 4 中。
步骤 6:信息合成和 LLM 增强
从图中检索到的上下文信息,连同原始查询和可能的初始候选文档,被综合成一个连贯的提示提供给 LLM。
这个丰富的提示为 LLM 提供了对用户请求的更深刻和更结构化的理解。
代码示例(Python):
ef synthesize_prompt(query, contextual_info, candidate_docs):
return "\n".join([
f"User Query: {query}",
"Relevant Context from Knowledge Graph:",
"\n".join(contextual_info),
"Additional Information from Documents:",
"\n".join(candidate_docs)
])
final_prompt = synthesize_prompt(query, context, candidate_docs)
print(f"\n📝 Final Prompt for LLM:\n{final_prompt}")
结果:

步骤 7:LLM 响应生成
最后,LLM 处理 增强的提示 并生成响应。
由于提示中包含丰富的上下文和相互关联的信息,LLM 更能提供准确、全面和连贯的答案。
代码示例(Python – 使用占位符 LLM 调用):
# Step 7: 模拟的 LLM 响应
def generate_llm_response(prompt):
if "Sundar" in prompt and "CEO of Google" in prompt:
return "Sundar Pichai is the CEO of Google. He oversees the company and has a significant net worth."
return "I need more information to answer that accurately."
llm_response = generate_llm_response(final_prompt)
print(f"\n💬 LLM Response: {llm_response}
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 3))
pos = nx.spring_layout(knowledge_graph)
nx.draw(knowledge_graph, pos, with_labels=True, node_color='skyblue', node_size=2000, font_size=12, font_weight='bold')
edge_labels = nx.get_edge_attributes(knowledge_graph, 'relation')
nx.draw_networkx_edge_labels(knowledge_graph, pos, edge_labels=edge_labels)
plt.title("Graph RAG: Knowledge Graph")
plt.show()
结果:


这个逐步过程,特别是动态图构建和遍历,使 Graph RAG 能够超越简单的关键词或语义相似性,对信息有更深刻的理解,并生成更优的响应。
图结构的整合为信息提供了强有力的上下文机制,这是实现高质量 RAG 输出的关键因素。
Graph RAG 的实用应用和使用案例
Graph RAG 不仅仅是一个理论概念;它理解并利用数据内部关系的能力在各个行业中开启了一系列实际应用。通过为 LLM 提供更丰富、更互联的上下文,Graph RAG 可以在传统 RAG 可能不足的情景中显著提升性能。以下是一些引人入胜的使用案例:
1. 强化企业知识管理
大型组织通常难以处理庞大的、不一致的知识库,包括内部文件、报告、维基和客户支持日志。传统搜索和 RAG 系统可以检索单个文件,但它们往往无法将不同孤岛之间的相关信息连接起来。
Graph RAG 可以构建一个动态知识图谱,将员工与项目、项目与文档、文档与概念、概念与外部法规或行业标准联系起来。
这使得:
- 员工智能问答: 员工可以提出复杂的问题,例如“项目 X 的合规要求是什么,哪些团队成员在这些领域是专家?” Graph RAG 可以遍历图来识别相关的合规文件,将它们链接到具体的法规,并然后找到与这些法规或项目 X 相关的员工。
- 自动化报告生成: 通过理解数据点之间的关系,Graph RAG 可以收集所有必要的信息来生成全面的报告,例如项目总结、风险评估或市场分析,从而显著减少人工努力。
- 入职和培训: 新员工可以通过查询知识库并获得丰富上下文信息的答案迅速熟悉情况,这些答案不仅解释某事物是什么,还解释它与其他内部流程、工具或团队的关系。
2. 高级法律和法规合规
法律和监管领域本质上是复杂的,其特点是大量的相互关联的文件、先例和法规。理解不同法律条款、案例法和监管框架之间的关系至关重要。Graph RAG 可以在这里带来革命性的变化:
- 合同分析: 律师可以使用 Graph RAG 来分析合同,识别关键条款、义务和风险,并将其与相关的法律先例或法规联系起来。像“显示我这份合同中与数据隐私相关的所有条款及其在 GDPR 下的影响”这样的查询可以通过遍历法律概念的图来全面回答。
- 法规影响评估: 当新法规引入时,Graph RAG 可以快速识别所有受影响的内部政策、业务流程,甚至特定项目,提供全面的合规影响视图。
- 诉讼支持: 通过在案件文件中映射实体之间的关系(例如,当事人、日期、事件、索赔、证据),Graph RAG 可以帮助法律团队快速识别联系,发现隐藏模式,并建立更强有力的论据。
3. 科学研究与药物发现
科学文献正以指数级增长,这使得研究人员难以跟上新的发现及其相互联系。Graph RAG 通过从科学论文、专利和临床试验数据中创建动态知识图谱来加速研究:
- 假设生成: 研究人员可以查询系统以获取潜在药物靶点、疾病途径或基因相互作用的信息。Graph RAG 可以将化合物、蛋白质、疾病和研究结果的信息连接起来,以提出新的假设或识别当前知识的空白。
- 文献综述: 与其筛选成千上万的论文,研究人员可以提出诸如“已知蛋白质 A 和疾病 B 之间的相互作用是什么,哪些研究小组正在积极研究这一领域?”等问题。然后,该系统可以提供有关相关发现和研究人员的结构化摘要。
- 临床试验分析: Graph RAG 可以将患者数据、治疗方案和结果联系起来,以识别可能不通过传统统计分析显而易见的相关性和见解,从而帮助药物开发和个性化医疗。
4. 智能客户支持和聊天机器人
虽然现在有许多聊天机器人存在,但它们的有效性通常受到其无法处理需要深刻语境理解的复杂、多轮对话的限制。Graph RAG 可以为新一代的客户支持系统提供动力:
- 复杂查询解决: 客户经常提出需要从多个来源组合信息的问题(例如,产品手册、常见问题解答、过去的支持票、用户论坛)。像“我的智能家居设备在最新的固件更新后无法连接到 Wi-Fi;有哪些故障排除步骤以及我的路由器型号的已知兼容性问题?”这样的查询可以通过一个理解设备、固件版本、路由器型号和故障排除程序之间关系的图谱 RAG 驱动的聊天机器人来解决。
- 个性化推荐: 通过了解客户的过去互动、偏好和产品使用情况(以图表示),该系统可以提供高度个性化的推荐产品或主动支持。
- 代理协助:客户服务代理可以从图谱增强代理系统(Graph RAG)中接收实时、上下文相关的信息和建议,显著缩短解决时间并提高客户满意度。
这些使用案例突显了 Graph RAG 在改变我们与信息互动的方式方面的潜力,超越了简单的检索,实现真正的上下文理解和智能推理。通过专注于数据之间的关系,Graph RAG 在 AI 驱动的应用程序中解锁了新的准确性、效率和洞察水平。
结论
Graph RAG 在检索增强生成领域代表了一次重要的演变,超越了传统基于向量的检索的局限性,利用互联知识的力量。通过动态构建和利用知识图谱,Graph RAG 使大型语言模型能够以前所未有的上下文深度和准确性访问和合成信息。
这种方法不仅增强了 LLM 响应的事实基础,还解锁了更复杂的推理、多跳问答以及对数据中复杂关系的更深入理解的潜力。
Graph RAG 的实际应用广泛且具有变革性,涵盖企业知识管理、法律和法规合规性、科学研究以及智能客户支持。在这些领域中,通过图结构来导航和理解错综复杂的信息网络,能够带来更精确、更全面和更可靠的 AI 驱动解决方案。随着数据的复杂性和互联性不断增加,Graph RAG 提供了一个强大的框架,用于构建能够真正理解和利用人类知识丰富网络的智能系统。
虽然在实现图 RAG 时可能会涉及克服与图构建、实体提取和高效遍历相关的挑战,但在增强 LLM 性能以及能够更有效地解决现实世界问题方面的益处是不可否认的。
随着该领域的研究和开发不断推进,码云笔记认为 Graph RAG 有望成为高级 AI 系统架构中不可或缺的组成部分,为未来 AI 能够以真正反映人类理解的智能水平进行推理和响应铺平道路。
常见问题
1. Graph RAG 相比传统 RAG 的主要优势是什么?
Graph RAG 的主要优势在于其能够理解并利用知识图谱中实体和概念之间的关系。与通常依赖向量空间语义相似性的传统 RAG 不同,Graph RAG 可以通过遍历显式连接来执行多跳推理并检索丰富上下文的信息,从而产生更准确和更全面的响应。
2. Graph RAG 如何处理新信息或不断发展的知识?
Graph RAG 采用动态知识图谱构建。它可以基于用户查询中识别出的实体和检索到的文档,实时构建或扩展知识图谱。这种实时处理能力使系统能够适应新信息和不断变化的上下文,而无需不断重新索引或手动更新图谱。
3. Graph RAG 是否适用于所有类型的数据?
Graph RAG 特别适用于实体间关系对理解和回答查询至关重要的数据。这包括可以转换为图表示的结构化、半结构化和非结构化文本。虽然它可以处理各种数据类型,但在信息互联丰富的领域中其优势最为显著,例如法律文件、科学文献或企业知识库。
4. 构建图 RAG 系统需要哪些主要组件?
典型的关键组件包括:
- 大语言模型 (LLM): 用于生成回复。
图数据库(或图表示库):用于存储和管理知识图谱(例如,Neo4j,Amazon Neptune,NetworkX)。 - 信息提取模块: 用于命名实体识别(NER)和关系提取(RE)以填充图。
检索模块:进行初步的文档检索,然后进行图遍历。 - 提示工程模块: 将检索到的图上下文合成一个连贯的提示,供 LLM 使用。
5. 在实施图 RAG 时可能遇到哪些潜在挑战?
挑战可能包括:
- 图构建的复杂性:从非结构化文本中准确提取实体和关系可能会具有挑战性。
- 可扩展性:高效地管理和遍历非常大的知识图谱在计算上可能非常密集。
- 数据质量:生成的图形的质量在很大程度上取决于输入数据和提取模型的质量。
- 集成:将各种组件(LLM、图数据库、NLP 工具)无缝集成可能需要大量的工程努力。
6. Graph RAG 可以与其他 RAG 技术结合使用吗?
可以,Graph RAG 可以与其他 RAG 技术结合。例如,初始检索仍然可以利用向量搜索来缩小相关文档集,然后将 Graph RAG 应用于这些候选文档,以构建更精确的上下文图。这种混合方法可以兼收并蓄:向量搜索的广泛覆盖和基于图的检索的深度上下文理解。
7. 在 Graph RAG 中,置信度评分是如何工作的?
在 Graph RAG 中,置信度评分涉及对动态构建的知识图谱中的节点和边进行评分。这些评分可以反映关系的强度、信息的新颖性或其来源的可靠性。系统使用这些评分来优先处理图遍历中的路径,确保仅检索和使用最相关和高质量的信息来增强 LLM 提示,从而最小化无关的添加。
以上关于GraphRAG:通过动态知识图谱提升人工智能的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » GraphRAG:通过动态知识图谱提升人工智能

