我是如何用 WebRTC + Whisper 实现语音识别?
随着 AI 的不断发展,越来越多的应用都开始引入 AI 来优化原本的 ⌈功能流程,用户体验⌋ 等,对于一名前端工程师来说,该如何融入到 AI 这个大环境中呢,如果你没有头绪,那不妨跟着本系列的步伐,我们一起去探探路~
上期我分享了 openAI 的语音识别模型 whisper 的使用体验,本期我们就来实践一下,在 web 端 来实现一个 语音识别 功能。
一、功能分析
首先我们可以先基于 web 端语音识别 这个功能点,提出两个问题
- 语音如何采集。即在程序中,我们如何获取到我们说的话(音频数据)
- 如何传输语音。如何将采集到的音频数据交给
whisper进行识别
这两个问题其实也很简单,都有成熟的解决方案
对于 语音采集,在 web 端 我们可以用浏览器基于 WebRTC 技术提供的流媒体相关接口调用麦克风来完成
对于 语音传输,当然还是走传统的 http,架设一个服务端提供 语音识别 接口来供前端调用
二、技术选型
基于上述简要的分析,web 应用部分比较简单
- 构建工具:
vite - 框架:
React - 组件库:
antd - 语音采集:recordrtc,
webm-to-wav-converter
由于 whisper 需要通过 python 调用,因此服务端基于 python 技术栈来做
三、实现过程
做好了相关技术栈的选定后,我们就开始着手搭建环境和编码
web 应用
为了测试 语音识别 这个功能,我们简单设计一下 UI
- 做一个
按钮来控制开始录音和结束录音 - 做一个
列表来展示每次录音的识别结果
OK,有了基本的设计,我们用 vite 的 react-ts 模板来初始化项目:
pnpm create vite whisper-demo-for-web --template react-ts
创建好项目之后,安装依赖,启动环境这些过程就不赘述了,我们直接进入编码阶段
首先来实现按钮部分,我们设计一个 RecordButtom 组件:
- 将
WebRTC的调用以及语音识别接口的调用一并封装在内 - 提供一个
onResult回调,用于返回识别结果
import React, { useState } from 'react';
import { Button, Spin } from 'antd';
import AudioRTC from "../sdk/AudioRTC";
import AudioAI from '../sdk/AudioAI';
// 定义识别结果
export type Result = {
// 识别内容 or 错误信息
text: string
// 识别耗时
transcribe_time?: number
}
type Props = {
// 识别完成事件
onResult?: (result: Result) => void;
}
// 状态枚举
enum Status {
// 空闲
IDLE = 'idle',
// 记录中
RECORDING = 'recording',
}
// 文本映射
const labelMapper = {
[Status.IDLE]: '开始录音',
[Status.RECORDING]: '停止录音',
}
// 过程转换映射
const processStatusMapper = {
[Status.IDLE]: Status.RECORDING,
[Status.RECORDING]: Status.IDLE,
}
// 初始化 AudioAI
const audioAI = new AudioAI();
// 初始化 AudioRTC
const audioRTC = new AudioRTC();
export default function RecordButton(props: Props) {
const [status, setStatus] = useState(Status.IDLE);
const [loading, setLoading] = useState(false);
// 点击事件
const onClick = async () => {
if (status === Status.IDLE) {
// 开始录制
audioRTC.startRecording();
}
if (status === Status.RECORDING) {
// 结束录制
await audioRTC.stopRecording();
// 获取 wav 格式的 blob
const waveBlob = await audioRTC.getWaveBlob();
try {
setLoading(true);
// 调用接口 - 语音识别
const response = await audioAI.toText(waveBlob)
props.onResult?.(response);
} catch (error) {
props.onResult?.({ text: `${error}` });
} finally {
setLoading(false)
}
}
setStatus(processStatusMapper[status]);
}
return (
<>
<Button onClick={onClick}>{labelMapper[status]}</Button>
{
loading &&
<Spin tip="识别中..." size="small">
<span className="content" />
</Spin>
}
</>
)
}
在按钮的实现过程中,我们又抽象了两个模块出来
AudioAI提供 AI 的处理能力,由于功能比较简单,只实现了一个 toText 方法,本质上是调用服务端接口,获取识别结果后返回// AudioAI.ts import { fetchAudioToText } from "./service"; export default class AudioAI { async toText(audio: Blob) { const response = await fetchAudioToText(audio) return response.data } }// service.ts import axios from 'axios' const api = axios.create({ baseURL: '/api', }) export const fetchAudioToText = async (audio: Blob) => { const formData = new FormData() formData.append('audio', audio) formData.append('timestamp', String(+new Date())) return api.post('/audioToText', formData) }AudioRTC封装调用流媒体的操作,提供开始录制,结束录制,获取音频流等相关 API// AudioRTC.ts import RecordRTC from 'recordrtc'; import { getWaveBlob } from 'webm-to-wav-converter' export default class AudioRTC { stream!: MediaStream; recorder!: RecordRTC /** * 开始录制 */ async startRecording() { if (!this.recorder) { this.stream = await navigator.mediaDevices.getUserMedia({ audio: true }) this.recorder = new RecordRTC(this.stream, { type: 'audio' }) } this.recorder.startRecording() } /** * 结束录制 * @returns */ stopRecording(): Promise<Blob> { if (!this.recorder) { return Promise.reject('Recorder is not initialized') } return new Promise((resolve) => { this.recorder.stopRecording(() => { const blob = this.recorder.getBlob() resolve(blob) }) }) } /** * 获取 blob * @returns */ getWaveBlob() { const blob = this.recorder.getBlob() return getWaveBlob(blob, false); } }
OK,按钮部分的编码至此结束,接下来就是列表部分的实现,由于比较简单,我们就直接写在 根组件 中,大致逻辑就是
- 存储一个 识别结果 列表
- 注册一个 onResult 事件,在收到识别结果时将其推入列表
- 渲染列表,列表项中展示
序号,识别耗时及内容等信息import { useState } from 'react' import './App.css' import RecordButton, { Result } from './components/RecordButton' import { Divider, List, Typography } from 'antd' function App() { const [list, setList] = useState<Result[]>([]) const onResult = (result: Result) => { setList((prev) => [...prev, result]) } return ( <div className="App"> <RecordButton onResult={onResult} /> <Divider orientation="left">识别记录</Divider> <List bordered dataSource={list} renderItem={(item, index) => ( <List.Item style={{ justifyContent: 'flex-start' }}> {/* 序号 */} <span>[{index + 1}]</span> {/* 耗时 */} <Typography.Text mark style={{ margin: '0 6px' }}> 识别耗时:{item.transcribe_time}s </Typography.Text> {/* 内容 */} <span style={{ margin: '0 6px' }}>{item.text}</span> </List.Item> )} /> </div> ) } export default App
以上就是 web 应用 的主要实现逻辑,接下来我们看下实际效果:
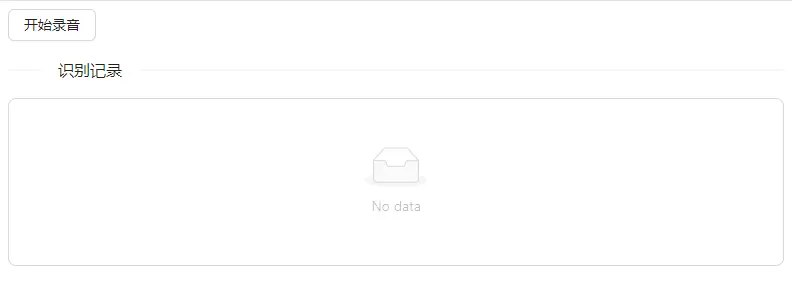
现在我们已经完成了一个简单页面,接下来就到了 服务端 的部分了
服务端
我们用 python 的 FastAPI 来快速实现一个 /audioToText 接口,这个接口具体需要做哪些工作呢?我们来分析一下
- 参数部分,接收一个
audio参数,类型是文件流;接收一个timestamp参数,是前端通过FormData传递的时间戳 - 功能部分,从文件流中读取到音频数据,交给
whisper去识别,然后将识别出的文本中的繁体字转为简体字,同时我们再分别记录一下这两步的耗时,提供一个参考指标
繁体转简体也有现成的库zhconv,所以这个接口的实现就很简单了,只需要把我们的业务流程组装起来即可
接下来我们开始编码:
# main.py
import time
import uvicorn
import io
import librosa
import zhconv
from fastapi import FastAPI, File, Form, UploadFile
from whisper_client import WhisperClient
app = FastAPI()
whisper = WhisperClient("medium")
@app.post('/audioToText')
def create_audio_to_text(
timestamp: str = Form(),
audio: UploadFile = File(...)
):
# 读取字节流
bt = audio.file.read()
# 转为 BinaryIO
memory_file = io.BytesIO(bt)
# 获取音频数据
data, sample_rate = librosa.load(memory_file, sr=None)
resample_data = librosa.resample(data, orig_sr=sample_rate, target_sr=16000)
transcribe_start_time = time.time()
# 语音识别
text = whisper.transcribe(resample_data)
transcribe_end_time = time.time()
convert_start_time = time.time()
# 繁体转简体
text = zhconv.convert(text, 'zh-hans')
convert_end_time = time.time()
return {
'status': 'ok',
'text': text,
'transcribe_time': transcribe_end_time - transcribe_start_time,
'convert_time': convert_end_time - convert_start_time
}
uvicorn.run(app, host="0.0.0.0", port=9090)
编码完成后,在终端启动一下服务来测试一下效果:
python main.py
三、效果演示
这里分别录入了两句话,都正确识别了:
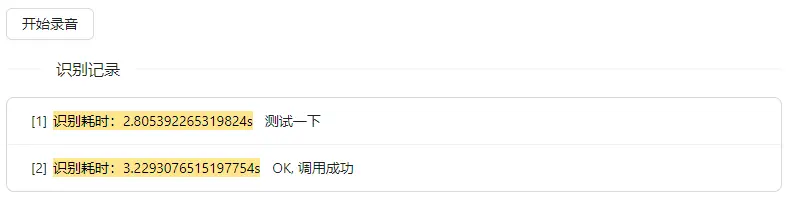
耗时方面则和机器的性能有关,在我们使用的这台测试机上 识别耗时 平均 3s 左右,体验稍差,这也说明进步空间。
结语
本期我们使用 WebRTC + Whisper 实现了一个简单 语音识别 功能,但实际应用中,语音识别 往往会结合 语音唤醒,降噪 等需求一起考虑,所以我们目前仅仅是完成了第一步
其实对于前端同学来说,python 几乎没有什么学习成本,结合 python 丰富的生态,快速开发一个 web 系统还是很轻松的,下期我们再继续分享~
原文:点击链接
以上关于我是如何用 WebRTC + Whisper 实现语音识别?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 我是如何用 WebRTC + Whisper 实现语音识别?