怎么在不停机的情况下保证迁移数据库数据的一致性?
数据迁移是系统演进中无法绕开的关键技术挑战。我注意到很多开发者在简历中会提到“负责过数据迁移项目”,但在面试中一旦深入追问,却往往说不清楚具体实施方案,或者只能给出“停机迁移”这种简单粗暴的答案。这其实小看了数据迁移这个面试点。数据迁移是一个能够综合体现你设计复杂方案解决棘手问题能力的绝佳场景,它能全面展示你在数据库原理、系统设计、风险控制等多方面的技术积累。今天,我将为你呈现一个完整的不停机数据迁移方案,并深入关键技术细节。
五大典型场景与价值
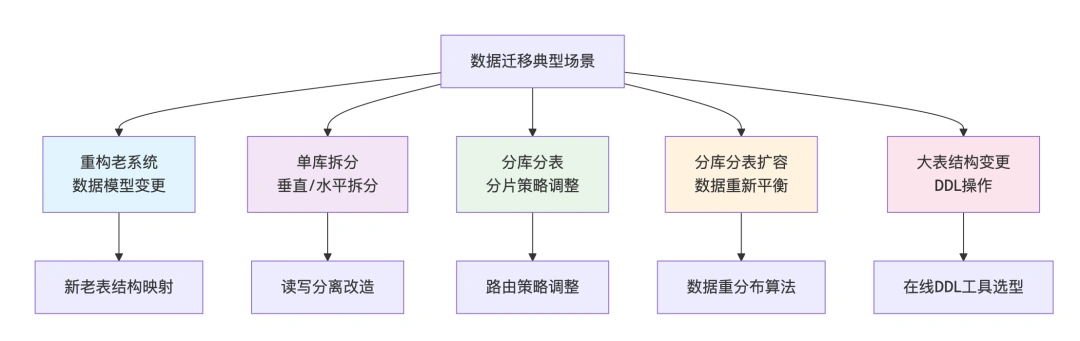
为什么这些场景如此重要?
重构老系统不只是技术债的偿还,更是业务发展到新阶段的必然选择。当数据模型从“用户-订单”简单关系到复杂的“用户-购物车-订单-物流-售后”网状关系时,迁移过程需要处理数据语义转换和业务逻辑适配的双重挑战。分库分表扩容看似只是增加机器,实则需要解决“数据热点”和“查询路由”两大难题。如何将 1 亿用户数据从 2 个分片平滑扩展到 4 个分片,同时保证用户无感知?这需要精妙的数据重分布算法和流量调度策略。
面试加分项:深入理解数据备份工具
在讨论迁移方案前,我们必须掌握基础工具。MySQL 领域有两款核心备份工具,它们的差异直接影响迁移方案的设计。
mysqldump:逻辑备份的利器
# 基本使用示例 mysqldump -h 主机 -u 用户 -p 密码 数据库 表 > backup.sql # 带优化参数的实战用法 mysqldump --single-transaction \ --master-data=2 \ --routines \ --events \ --quick \ --skip-add-drop-table \ 数据库名 > backup.sql
mysqldump 核心特点:
- 逻辑备份:导出的是 SQL 语句,可读性强;
- 跨版本兼容:高版本导出可导入低版本(需注意语法兼容性);
- 选择性备份:可备份特定表、忽略特定表;
- 主要缺点:大数据量时导出导入慢,锁表风险。
XtraBackup:物理备份的专业选择
# 全量备份 innobackupex --user=用户名 --password=密码 /备份路径/ # 增量备份 innobackupex --user=用户名 --password=密码 \ --incremental /增量备份路径/ \ --incremental-basedir=/上次全备路径/ # 准备恢复 innobackupex --apply-log /备份路径/
XtraBackup 核心优势:
- 物理备份:直接复制数据文件,速度极快;
- 热备份:不锁表,不影响业务运行;
- 增量备份:只备份变化的数据,节省空间和时间;
- 流式备份:支持边备份边传输到远程。
工具选择策略
小型数据库(<50GB):mysqldump 足够,简单可靠大型数据库(>50GB):XtraBackup 是必选,特别是需要快速恢复的场景混合场景:结构用 mysqldump,数据用 XtraBackup 云数据库:优先使用云厂商的备份服务(如 RDS 的快照功能)
innodb_autoinc_lock_mode
在数据迁移,特别是双写阶段,自增主键的生成策略会直接影响数据一致性。MySQL 的 innodb_autoinc_lock_mode 参数控制着自增锁的行为,理解它至关重要。
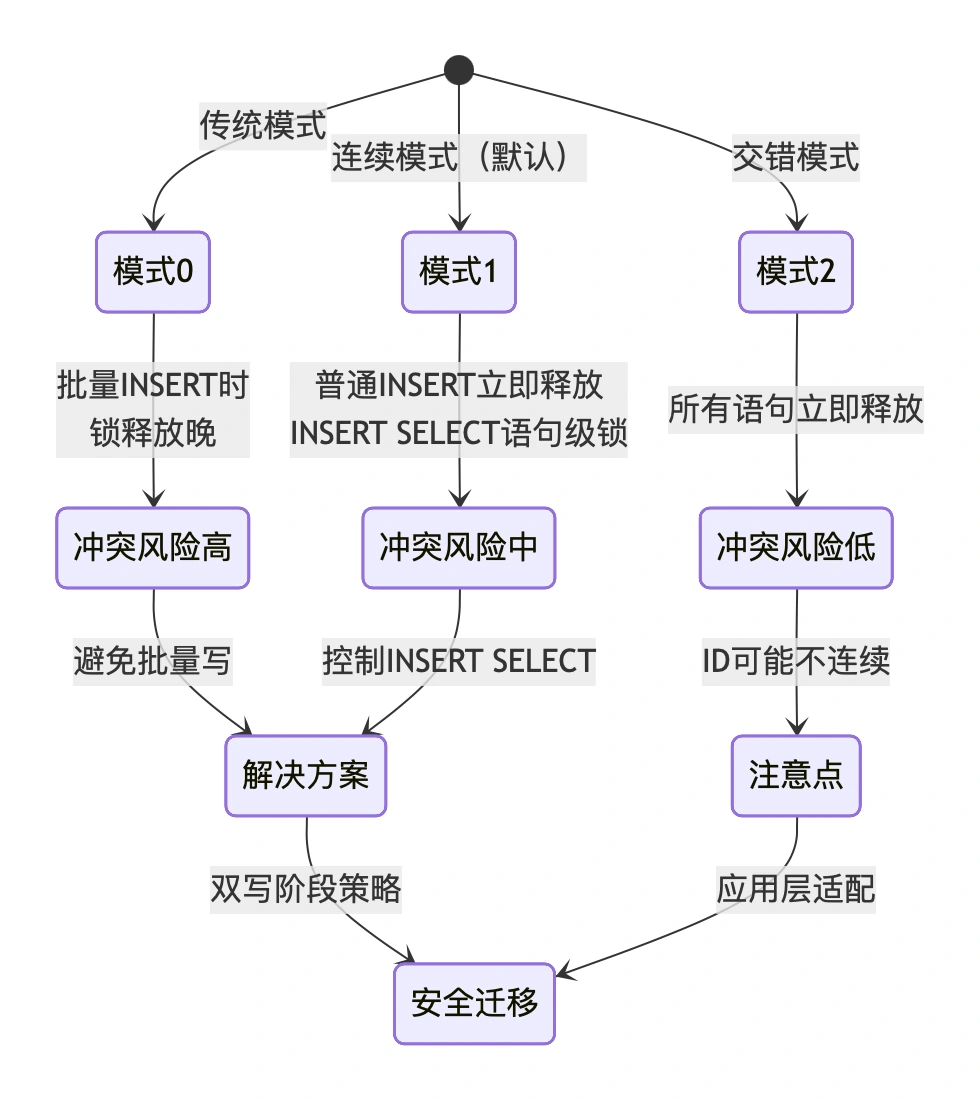
模式 0:传统模式
-- 示例:任何 INSERT 语句都会持有自增锁直到语句结束
INSERT INTO users (name) VALUES ('张三'), ('李四'), ('王五');
-- 整个语句执行期间都持有自增锁
迁移影响:在双写阶段,如果新旧表都使用模式 0,批量插入可能导致严重的锁竞争,影响写入性能。
模式 1:连续模式(默认值)
-- 普通 INSERT:立即释放锁
INSERT INTO users (name) VALUES ('张三');
-- 申请到 ID=1 后立即释放锁
-- INSERT SELECT:语句结束释放
INSERT INTO users (name)
SELECT name FROM temp_users WHERE id > 1000;
-- 整个 SELECT 执行期间都持有锁
迁移影响:这是最常用的设置。在迁移中需要注意 INSERT INTO … SELECT 这类语句,可能成为性能瓶颈。
模式 2:交错模式
-- 所有 INSERT 都立即释放锁
INSERT INTO users (name) VALUES ('张三'), ('李四');
-- 可能 ID 为 1,3(不连续)
迁移影响:性能最好,但 ID 不连续。在双写时,如果新旧表使用不同模式,可能导致数据不一致。迁移场景下的最佳实践
// 错误的双写做法:依赖数据库自增 ID
public Long saveUser(User user) {
// 旧表插入
Long oldId = oldMapper.insert(user); // 返回 ID=100
// 新表插入
user.setId(oldId); // 直接使用旧 ID
newMapper.insert(user); // 可能失败,如果 ID 已存在
return oldId;
}
// 正确的做法:统一 ID 生成策略
public Long saveUser(User user) {
// 使用分布式 ID 生成器
Long newId = idGenerator.nextId();
user.setId(newId);
// 双写
oldMapper.insert(user);
newMapper.insert(user);
return newId;
}
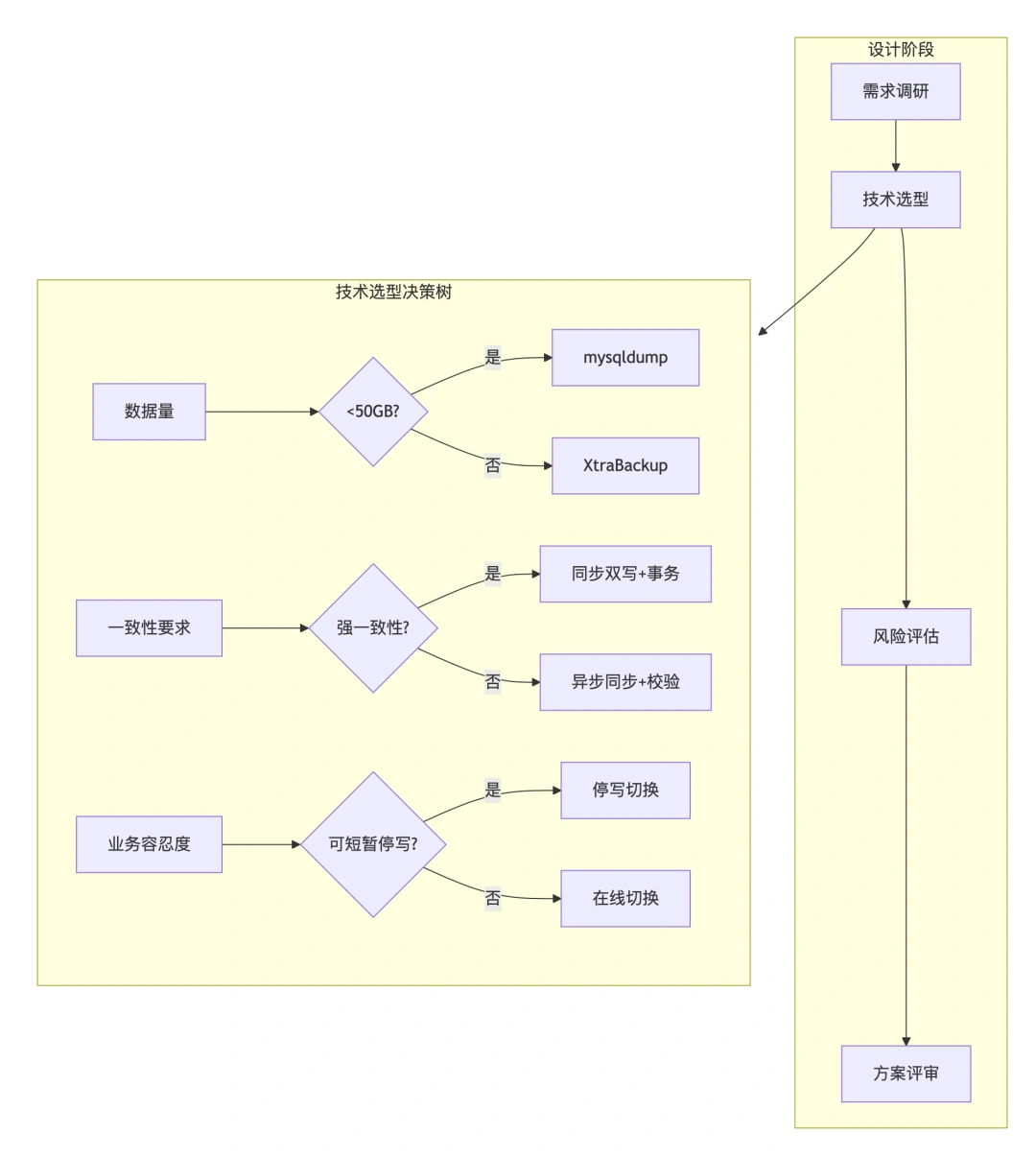
不停机迁移方案
方案设计与评估
面试官常问:“如果让你设计一个数据迁移方案,你会考虑哪些方面?”标准回答结构:
- 业务影响分析:迁移范围、数据量、业务峰值;
- 技术选型理由:为什么选 A 而不是 B;
- 风险评估矩阵:识别高风险点及应对措施;
- 回滚方案:具体步骤和时间预估。
阶段二:环境准备与数据初始化(工具实战)
全量迁移的优化技巧:
-- 1. 分批迁移,避免大事务 SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SET @@sql_select_limit = 10000; -- 2. 无锁导出(需要一致性视图) mysqldump --single-transaction --skip-lock-tables -- 3. 并行导入 mysql --host=新库 --port=3306 --user=root -p \ --default-character-set=utf8mb4 \ --max-allowed-packet=512M \ database < backup.sql & # 使用 parallel 加速 cat backup.sql | parallel --pipe -N 1000 mysql -h 新库 -u 用户 -p 密码 database
增量同步的开启时机:
# 1. 记录全量备份开始的 Binlog 位置
mysqldump --master-data=2 > backup.sql
# 查看备份文件开头,记录 MASTER_LOG_FILE 和 MASTER_LOG_POS
# 2. 配置 Canal 或 Debezium 从该位置开始同步
canal.instance.master.journal.name = ${MASTER_LOG_FILE}
canal.instance.master.position = ${MASTER_LOG_POS}
阶段三:双写与数据同步
双写模式的选择:
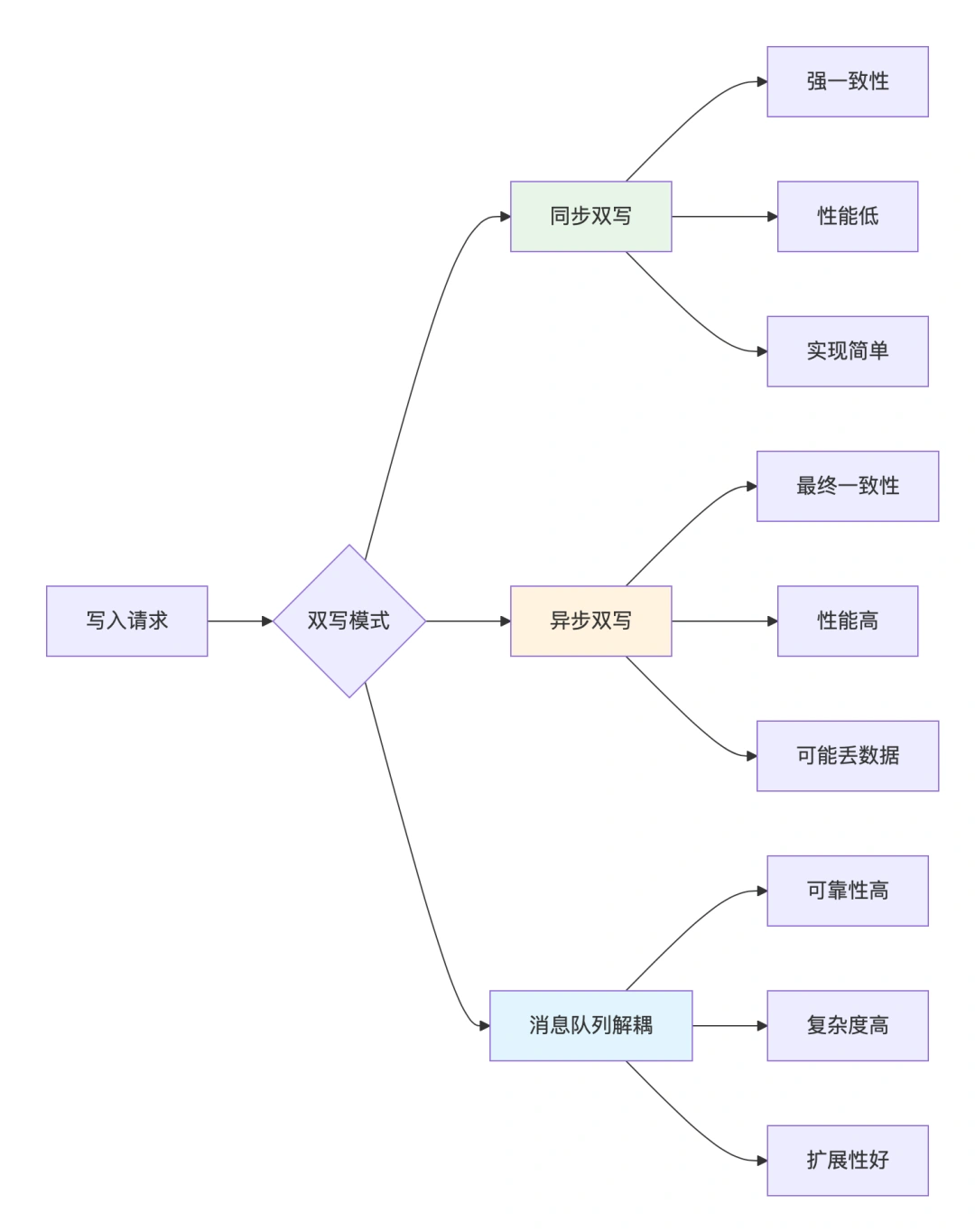
同步双写实现示例:
@Component
publicclass DualWriteService {
// 使用 Spring 的@Transactional 确保原子性
@Transactional(rollbackFor = Exception.class)
public void saveWithDualWrite(User user) {
try {
// 先写旧库
oldDao.insert(user);
// 再写新库
newDao.insert(user);
// 记录操作日志(用于一致性校验)
OperationLog log = new OperationLog();
log.setType("INSERT");
log.setDataId(user.getId());
log.setCreateTime(new Date());
logService.record(log);
} catch (Exception e) {
// 记录失败日志,触发告警
alertService.sendAlert("双写失败: " + e.getMessage());
throw e;
}
}
// 引入版本号解决更新冲突
public void updateWithVersion(User user) {
// 从旧库读取当前版本
int oldVersion = oldDao.getVersion(user.getId());
if (user.getVersion() != oldVersion) {
thrownew OptimisticLockException("数据已变更");
}
// 版本号+1
user.setVersion(oldVersion + 1);
// 双写更新
oldDao.update(user);
newDao.update(user);
}
}
数据一致性校验的多种策略:
class DataConsistencyChecker:
def full_check(self):
"""全量校验:适合数据量小的场景"""
# 分批对比,避免内存溢出
batch_size = 10000
for i in range(0, total_count, batch_size):
old_data = old_db.query("LIMIT ?, ?", i, batch_size)
new_data = new_db.query("LIMIT ?, ?", i, batch_size)
diff = self.compare_batch(old_data, new_data)
if diff:
self.repair(diff)
def incremental_check(self):
"""增量校验:基于 Binlog 或操作日志"""
# 监听变更事件
for change_event in change_stream:
# 验证新库中是否存在对应记录
old_record = old_db.get_by_id(change_event.id)
new_record = new_db.get_by_id(change_event.id)
ifnot self.is_equal(old_record, new_record):
self.trigger_alarm(change_event)
def sampling_check(self):
"""抽样校验:适合大数据量场景"""
# 随机抽样 N 条记录
sample_ids = self.random_sample(1000)
for id in sample_ids:
old = old_db.get_by_id(id)
new = new_db.get_by_id(id)
ifnot self.is_equal(old, new):
# 对该 ID 的相关记录进行全量校验
self.deep_check(id)
def checksum_check(self):
"""校验和:快速验证大批量数据"""
# 计算某个时间点后的数据校验和
old_checksum = old_db.query("""
SELECT COUNT(*) as cnt,
SUM(CRC32(CONCAT_WS(',', id, name, age))) as sum
FROM users
WHERE update_time > '2024-01-01'
""")
new_checksum = new_db.query("""
SELECT COUNT(*) as cnt,
SUM(CRC32(CONCAT_WS(',', id, name, age))) as sum
FROM users_new
WHERE update_time > '2024-01-01'
""")
return old_checksum == new_checksum
阶段四:读流量切换
多维度的灰度策略:
public class TrafficRouter {
// 1. 按用户 ID 分片
public boolean shouldRouteToNew(Long userId) {
// 前 10%的用户灰度
return userId % 10 == 0;
}
// 2. 按业务类型
public boolean isReadOnlyQuery(String sql) {
return sql.startsWith("SELECT");
}
// 3. 按流量比例(动态调整)
private AtomicInteger routingPercentage = new AtomicInteger(1); // 初始 1%
public boolean shouldRouteByPercentage() {
int random = new Random().nextInt(100);
return random < routingPercentage.get();
}
// 动态调整百分比
public void adjustPercentage(int newPercent) {
if (newPercent >= 0 && newPercent <= 100) {
routingPercentage.set(newPercent);
}
}
// 4. 基于熔断器的自动回退
public Object routeWithFallback(String sql, Object params) {
try {
if (shouldRouteToNew()) {
return newDb.query(sql, params);
} else {
return oldDb.query(sql, params);
}
} catch (Exception e) {
// 新库异常,自动降级到旧库
log.warn("新库查询失败,降级到旧库", e);
return oldDb.query(sql, params);
}
}
}
监控指标看板:
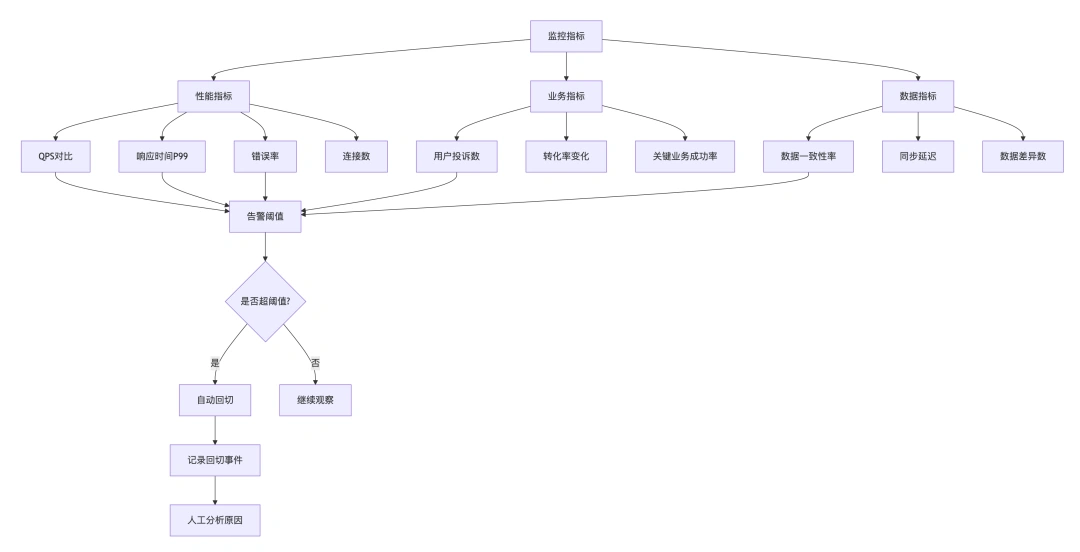
阶段五:写流量切换与双写下线
平滑切换的关键步骤:
#!/bin/bash
# 写流量切换脚本
# 1. 前置检查
check_prerequisites() {
# 检查新库健康状况
if ! check_new_db_health; then
echo "新库健康状况检查失败"
exit 1
fi
# 检查同步延迟
delay=$(get_replication_delay)
if [ $delay -gt 10 ]; then
echo "同步延迟过大: ${delay}秒"
exit 1
fi
# 检查业务低峰期
if ! is_low_traffic_period; then
echo "当前不是业务低峰期"
exit 1
fi
}
# 2. 停写旧库
stop_write_to_old() {
# 通过配置中心动态调整
curl -X PUT "http://config-center/write-switch" \
-d '{"old_write_enabled": false}'
# 等待进行中的请求完成
sleep 30
# 验证旧库无新写入
if has_new_writes_old; then
echo "旧库仍有新写入,切换失败"
rollback_switch
exit 1
fi
}
# 3. 最终一致性校验
final_consistency_check() {
# 对比停写时间点的数据快照
snapshot_time=$(date +%s)
take_snapshot old_db $snapshot_time
take_snapshot new_db $snapshot_time
diff_result=$(compare_snapshots)
if [ "$diff_result" != "一致" ]; then
echo "最终一致性校验失败: $diff_result"
rollback_switch
exit 1
fi
}
# 4. 切换完成
switch_complete() {
# 更新路由配置,所有流量到新库
update_router_config
# 关闭双写逻辑
disable_dual_write
# 发送通知
send_notification "写流量切换完成"
# 启动旧库归档任务
start_archive_job
}
阶段六:监控与优化
# 监控配置 monitoring: data_quality: # 定期抽样检查 sampling_check: enabled:true cron:"0 2 * * *"# 每天凌晨 2 点 sample_size:10000 # 关键业务数据检查 business_check: enabled:true checks: -name:"用户余额一致性" sql:"SELECT COUNT(*) FROM old.accounts WHERE balance != new.accounts.balance" threshold:0 -name:"订单状态一致性" sql:"SELECT COUNT(*) FROM old.orders o JOIN new.orders n ON o.id=n.id WHERE o.status != n.status" threshold:0 performance: # 新库性能基准 baseline: qps:10000 p99_latency:100 error_rate:0.01 # 自动扩容规则 auto_scaling: -metric:"cpu_usage" threshold:70 action:"add_slave" -metric:"disk_usage" threshold:80 action:"alert" alarm: # 告警规则 rules: -name:"数据不一致告警" condition:"data_inconsistency > 0" channels:["sms","email","wechat"] -name:"同步延迟告警" condition:"replication_delay > 30" channels:["sms","dashboard"] -name:"业务错误率告警" condition:"error_rate > 1%" channels:["phone","dashboard"]
面试常见问题深度解析
问题 1:双写期间如果遇到数据冲突,如何解决?冲突场景分析:
// 场景 1:同一记录被两个请求同时更新
// 请求 A:更新用户余额为 100
// 请求 B:更新用户余额为 200
// 结果:最终余额应该是多少?
// 解决方案:使用乐观锁
public boolean updateBalance(Long userId, BigDecimal newBalance, int version) {
String sql = """
UPDATE accounts
SET balance = ?, version = version + 1
WHERE user_id = ? AND version = ?
""";
int rows = jdbcTemplate.update(sql, newBalance, userId, version);
return rows > 0;
}
// 场景 2:新旧库 ID 生成策略不同导致冲突
// 解决方案:使用分布式 ID 生成器
publicclass DistributedIdGenerator {
// Twitter Snowflake 算法
public Long nextId() {
long timestamp = System.currentTimeMillis();
long sequence = getNextSequence();
return ((timestamp - 1288834974657L) << 22) |
(dataCenterId << 17) |
(workerId << 12) |
sequence;
}
}
问题 2:如何评估迁移是否成功?具体评估维度:
- 数据维度(权重 40%)
- 一致性率:>99.99%
- 同步延迟:<1 秒
- 数据差异数:0
- 性能维度(权重 30%)
- 查询响应时间:不高于迁移前
- 写入 TPS:不低于迁移前
- 系统资源使用率:正常范围内
- 业务维度(权重 30%)
- 用户投诉:0 增长
- 关键业务成功率:100%
- 监控告警:无新增告警
问题 3:如何设计回滚方案?回滚决策树:
def should_rollback(metrics):
"""
判断是否需要回滚
:param metrics: 监控指标
:return: (是否回滚, 回滚级别)
"""
# 级别 1: 数据不一致
if metrics.data_inconsistency > 1000: # 超过 1000 条不一致
returnTrue, "LEVEL_1"# 立即回滚
# 级别 2: 性能严重下降
if metrics.error_rate > 5or metrics.p99_latency > 1000:
returnTrue, "LEVEL_2"# 5 分钟内回滚
# 级别 3: 业务影响
if metrics.user_complaints > 10or metrics.business_success_rate < 99:
returnTrue, "LEVEL_3"# 30 分钟内回滚
returnFalse, None
# 分级回滚策略
ROLLBACK_STRATEGY = {
"LEVEL_1": {
"action": "立即停写新库,恢复旧库写",
"timeout": "5 分钟",
"负责人": "值班 SRE"
},
"LEVEL_2": {
"action": "逐步切回读流量,再切回写",
"timeout": "30 分钟",
"负责人": "DBA+开发"
},
"LEVEL_3": {
"action": "分析问题,制定回滚计划",
"timeout": "2 小时",
"负责人": "技术负责人"
}
}
总结
1. 必知必会的知识点
- 备份工具原理:mysqldump vs XtraBackup 的实现差异
- 数据同步技术:Binlog 原理、CDC 实现、消息队列应用
- 一致性保障:最终一致性实现、冲突解决算法
- 性能优化:分批处理、并行化、索引优化
2. 项目经验包装
不要只说“我做过数据迁移”,要具体说明:
✗ 不好的回答:我负责过用户数据迁移
✓ 好的回答:我主导了千万级用户数据从 MySQL 到分库分表的迁移
– 设计了双写+增量同步方案,迁移期间零停机
– 实现了数据一致性校验系统,自动修复率 95%
– 通过灰度发布将风险降到最低,最终无故障完成迁移
3. 系统设计能力体现
面试中可能会让你设计一个迁移方案,可以按此结构回答:
1. 需求澄清 - 数据规模:表数量、数据量、增长速度 - 业务要求:允许的停机时间、一致性要求 - 现有架构:当前数据库架构、业务特点 2. 方案设计 - 整体架构:图示说明各组件关系 - 技术选型:为什么选这个方案 - 关键决策:双写策略、切换方式等 3. 实施细节 - 阶段划分:明确每个阶段的目标和验收标准 - 风险控制:可能的风险和应对措施 - 监控报警:如何确保问题及时发现 4. 验证方案 - 如何验证迁移成功 - 回滚方案是什么 - 如何评估业务影响
数据迁移这个面试点之所以重要,是因为它能全面考察一个工程师的:
- 技术深度:对数据库原理、分布式系统的理解
- 工程能力:设计可实施、可监控、可回滚的方案
- 风险意识:预见问题、制定预案、控制影响
- 沟通协调:跨团队协作、进度同步、应急处理
记住,面试官想看到的不仅是你做过什么,更是你思考问题的方式。面对“如何做数据迁移”这个问题,展现你从业务需求分析,到技术方案设计,再到风险控制评估的完整思考过程,这才是真正的加分项。最后的小提示:在面试前,务必在自己的环境中实际操作一遍数据迁移的完整流程。理论知识再丰富,也比不上亲手踩过一个坑。当你能够清晰描述迁移过程中的每个细节、每个决策背后的思考时,这个面试点就已经成为你的优势所在了。
以上关于怎么在不停机的情况下保证迁移数据库数据的一致性?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 怎么在不停机的情况下保证迁移数据库数据的一致性?