
一个 try-catch 愣是让面试官问出这么多花样?
刚刚面试回来的 B 哥又在吐槽了:现在的面试官太难伺候了,放着好好的堆、栈、方法区不问,上来就让我从字节码角度给他分析一下try-catch-finally(以下简称 TCF)的执行效率。
我觉得应该是面试官在面试的过程中看大家背的八股文都如出一辙,觉得没有问的必要,便拐着弯地考大家的理解。
今天趁着 B 哥也在,我们就来好好总结一下 TCF 相关的知识点,期待下次与面试官对线五五开!
环境准备:IntelliJ IDEA 2020.2.3、JDK 1.8.0_181
执行顺序
我们先来写一段简单的代码:
public static int test1() {
int x = 1;
try {
return x;
} finally {
x = 2;
}
}
答案是 1 不是 2,你答对了吗?
大家都知道在 TCF 中,执行到return的时候会先去执行finally中的操作,然后才会返回来执行return,那这里为啥会是 1 呢?我们来反编译一下字节码文件。
使用命令:
javap -v xxx.class
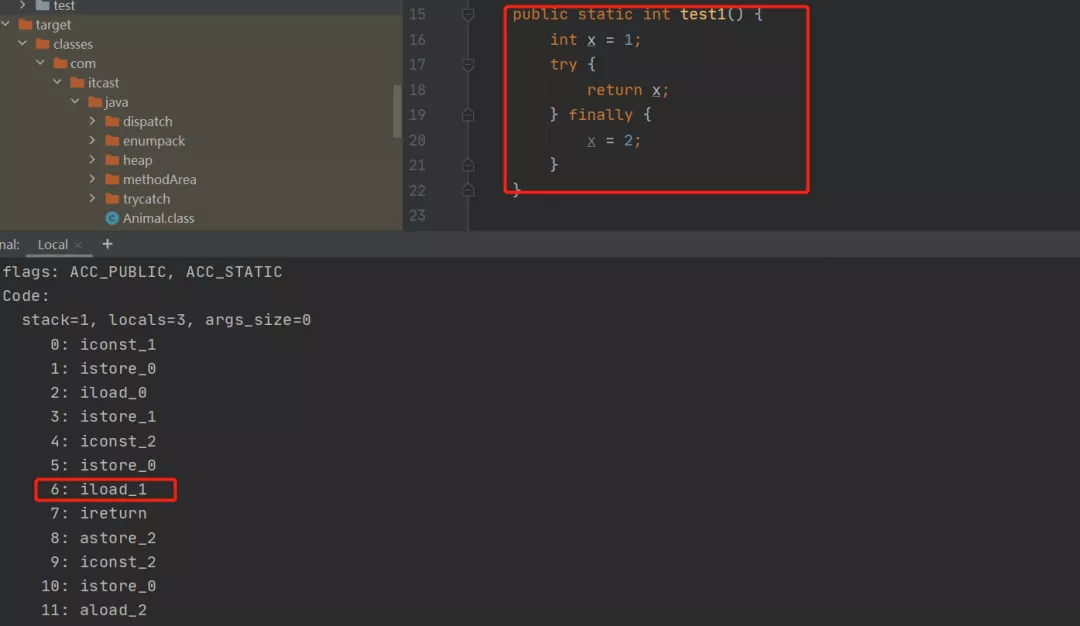
字节码指令晦涩难懂,那我们就用图解的方式来解释一下(我们先只看前 7 行指令):首先执行 int x = 1;。
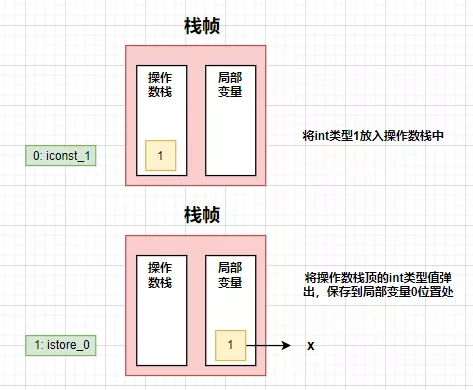
然后我们需要执行try中的return x;。
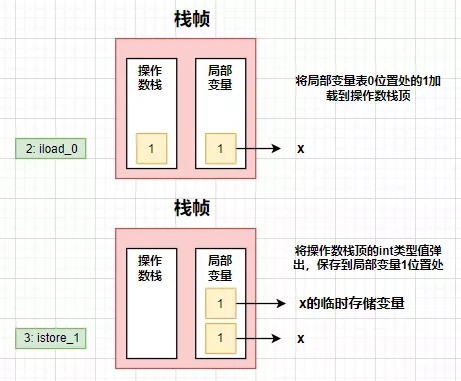
此时并不是真正的返回x的值,而是将x的值存到局部变量表中作为临时存储变量进行存储,也就是对该值进行保护操作。
最后进入finally中执行x=2;。
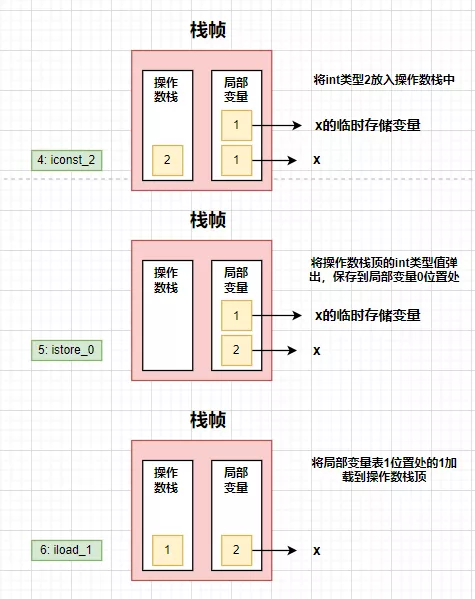
此时虽然x已经被赋值为 2 了,但是由于刚才的保护操作,在执行真正的return操作时,会将被保护的临时存储变量入栈返回。
为了更好地理解上述操作,我们再来写一段简单代码:
public static int test2() {
int x = 1;
try {
return x;
} finally {
x = 2;
return x;
}
}
大家思考一下执行结果是几?答案是 2 不是 1。
我们再来看下该程序的字节码指令。
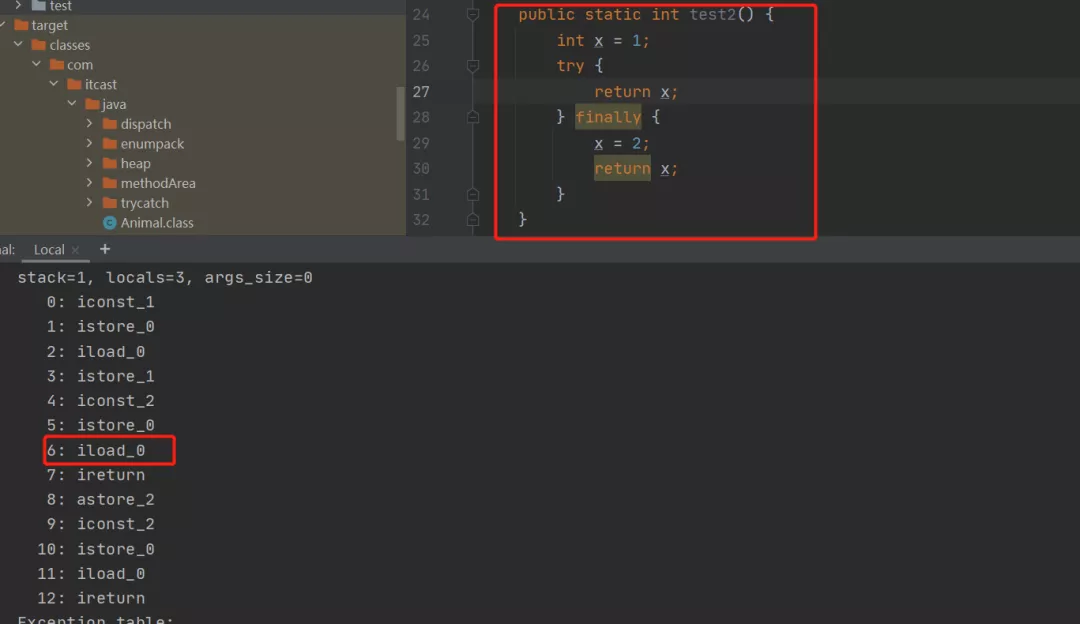
通过对比发现,第 6 行一个是iload_1,一个是iload_0,这是由什么决定的呢?原因就是我们上边提到的保护机制,当在finally中存在return语句时,保护机制便会失效,转而将变量的值入栈并返回。
小结
return的执行优先级高于finally的执行优先级,但是return语句执行完毕之后并不会马上结束函数,而是将结果保存到栈帧中的局部变量表中,然后继续执行finally块中的语句。- 如果
finally块中包含return语句,则不会对try块中要返回的值进行保护,而是直接跳到finally语句中执行,并最后在finally语句中返回,返回值是在finally块中改变之后的值。
finally 为什么一定会执行?
细心的小伙伴应该能发现,上边的字节码指令图中第 4-7 行和第 9-12 行的字节码指令是完全一致的,那么为什么会出现重复的指令呢?
首先我们来分析一下这些重复的指令都做了些什么操作。经过分析发现它们就是x = 2;return x;的字节码指令,也就是finally代码块中的代码。由此我们有理由怀疑如果上述代码中加入catch代码块,finally代码块对应的字节码指令也会再次出现。
public static int test2() {
int x = 1;
try {
return x;
} catch(Exception e) {
x = 3;
} finally {
x = 2;
return x;
}
}
反编译之后:
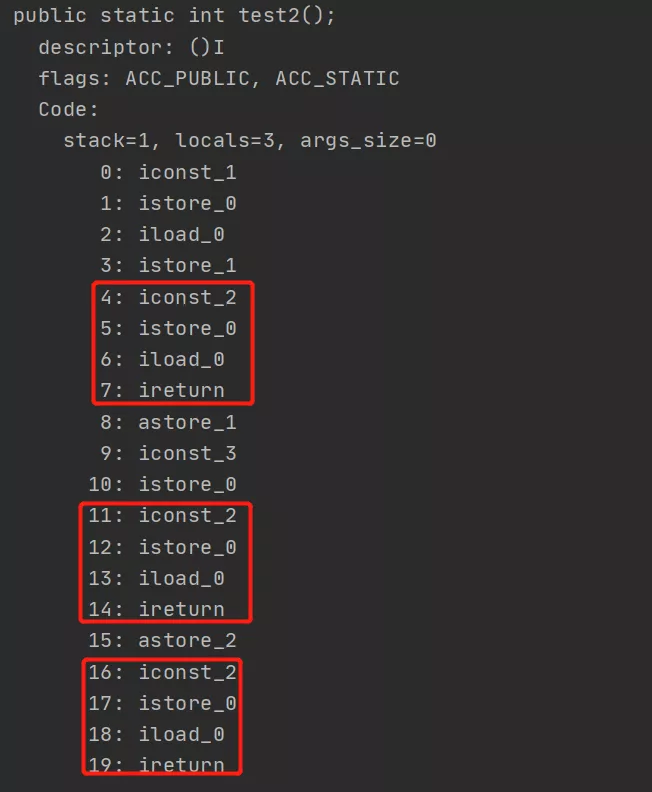
果然如我们所料,重复的字节码指令出现了三次。让我们回归到最初的问题上,为什么finally代码的字节码指令会重复出现三次呢?
原来是JVM为了保证所有异常路径和正常路径的执行流程都要执行finally中的代码,所以在try和catch后追加上了finally中的字节码指令,再加上它自己本身的指令,正好三次。这也就是为什么finally 一定会执行的原因。
finally 一定会执行吗?
为什么上边已经说了finally中的代码一定会执行,现在还要再多此一举呢?请看:👇
在正常情况下,它是一定会被执行的,但是至少存在以下三种情况,是一定不执行的:
try语句没有被执行到就返回了,这样finally语句就不会执行,这也说明了finally语句被执行的必要而非充分条件是:相应的try语句一定被执行到。try代码块中有System.exit(0);这样的语句,因为System.exit(0);是终止JVM的,连JVM都停止了,finally肯定不会被执行了。- 守护线程会随着所有非守护线程的退出而退出,当守护线程内部的
finally的代码还未被执行到,非守护线程终结或退出时,finally肯定不会被执行。
TCF 的效率问题
说起 TCF 的效率问题,我们不得不介绍一下异常表,拿上边的程序来说,反编译class文件后的异常表信息如下:
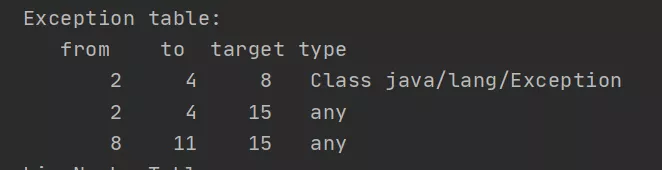
- from:代表异常处理器所监控范围的起始位置。
- to:代表异常处理器所监控范围的结束位置(该行不被包括在监控范围内,是前闭后开区间)。
- target:指向异常处理器的起始位置。
- type:代表异常处理器所捕获的异常类型。
图中每一行代表一个异常处理器。
工作流程
- 触发异常时,
JVM会从上到下遍历异常表中所有的条目。 - 比较触发异常的行数是否在
from–to范围内。 - 范围匹配之后,会继续比较抛出的异常类型和异常处理器所捕获的异常类型
type是否相同。 - 如果类型相同,会跳转到
target所指向的行数开始执行。 - 如果类型不同,会弹出当前方法对应的
java栈帧,并对调用者重复操作。 - 最坏的情况下,
JVM需要遍历该线程Java栈上所有方法的异常表。
拿第一行为例:如果位于 2-4 行之间的命令(即try块中的代码)抛出了Class java/lang/Exception类型的异常,则跳转到第 8 行开始执行。
8: astore_1是指将抛出的异常对象保存到局部变量表中的 1 位置处。
从字节码指令的角度来讲,如果代码中没有异常抛出,TCF 的执行时间可以忽略不计;如果代码执行过程中出现了上文中的第 6 条,那么随着异常表的遍历,更多的异常实例被构建出来,异常所需要的栈轨迹也在生成。该操作会逐一访问当前线程的栈帧,记录各种调试信息,包括类名、方法名、触发异常的代码行数等等,所以执行效率会大大降低。
看到这儿,你是否对 TCF 有了更加深入的了解呢?
以上关于一个 try-catch 愣是让面试官问出这么多花样?的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 一个 try-catch 愣是让面试官问出这么多花样?