MySQL 9.5 性能优化终极指南:从 10s 到 10ms 的 5 个核心心法
今天,码哥带你深入 MySQL 的内心世界,扒一扒这个每天被你“增删改查”的老伙计,到底怎么才能跑得比香港记者还快!
咱都是实干派,不整那些虚头巴脑的理论。直接上硬菜,告诉你为啥你的 SQL 写得跟树懒一样慢,以及怎么给它装上火箭推进器。
“友情提示:码哥宣言:只讲官网最硬核的实战,不搞理论废话。要是看完没收获,码哥我当场……给你再讲一遍!
想象一下这个场景:月黑风高夜,你和对象(如果有的话)正在享受甜蜜时光。突然,报警短信“哔哔哔”响个不停——线上服务挂了一大片!
你火急火燎地打开监控一看,CPU 100%,数据库连接池爆满,无数请求在超时的边缘疯狂试探。你脑海中瞬间闪过三个字:慢查询!
别慌,码哥教你 MySQL 性能优化的“太极心法”:化 I/O 于无形,锁争用于无声。下面这套“组合拳”,请你接好。
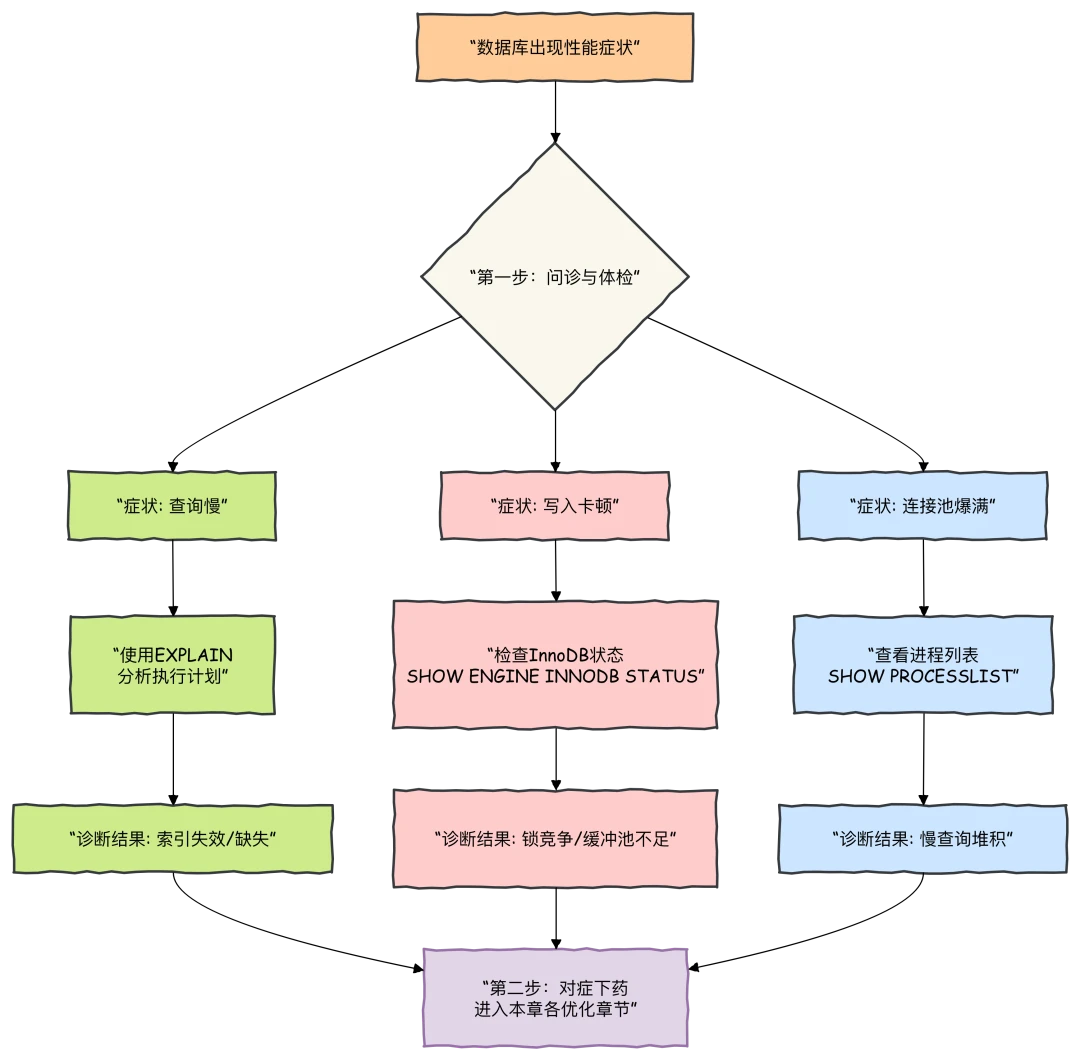
数据库性能取决于数据库层面的多个因素,例如表结构、查询语句和配置设置。
这些软件层面的设计最终会转化为硬件层面的 CPU 和 I/O 操作,必须尽可能减少这些操作并提升其效率。
在进行数据库性能优化时,首先需要掌握软件层面的高级规则与指导原则,并通过实际耗时来评估性能。
随着经验积累,你将深入了解内部运行机制,并开始通过测量 CPU 周期和 I/O 操作等指标进行精准优化。
表结构设计
你想想,要是让姚明去住幼儿园的小床,他能睡得舒服吗?你的数据也是同理。
表结构就是数据的家,设计得好,数据住得舒坦,查询速度自然起飞。
数据类型:能小就别大,能瘦就别胖
- TINYINT 是你的好朋友:存状态码(0/1),用 TINYINT,别用 INT!省下来的每一字节,都是为未来节省一次磁盘 I/O。
- 用 DATE 代替 DATETIME:如果你不关心时分秒,就别让它们占着茅坑不拉屎。
- 避免“Null 的诅咒”:NULL 是个磨人的小妖精,它会让索引、计算都变得更复杂。尽量给列设置个默认值(比如空字符串,0)。
- 字符串类型优化:IP 地址可以存储为无符号整数;UUID 可以存储为 BINARY(16);固定长度字符串使用 CHAR;可变长度字符串使用 VARCHAR 并设置合适长度。
- 时间类型优化:只需要日期时使用 DATE 类型;需要自动更新时间戳时使用 TIMESTAMP。
- 码哥划重点:更小的数据类型 → 更少的磁盘空间 → 更多数据能塞进内存 → 更少的 I/O → 飞一样的速度。这叫因果律武器.
范式与反范式
- 范式化(高范式):好比夫妻财政 AA 制,账目清晰,更新自由(写操作快)。适合写多读少的场景。
- 反范式化(低范式):好比夫妻钱放一个兜,用起来方便,不用来回要(读操作快,避免 JOIN)。适合读多写少的场景。
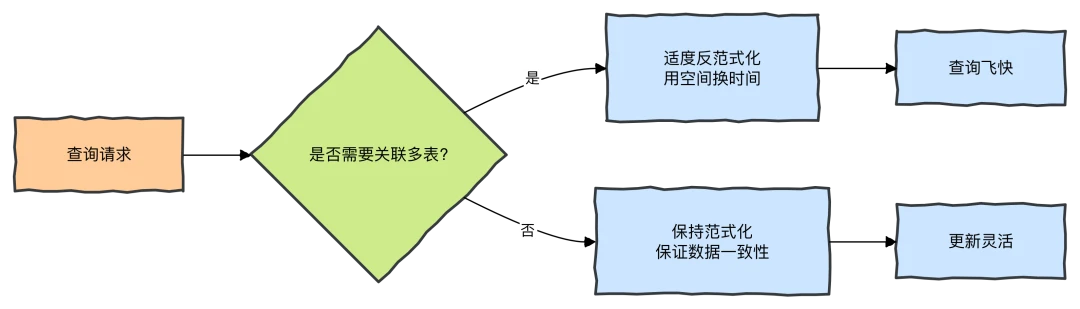
没有绝对的好坏,只有适不适合。在需要极致查询速度时,适度冗余,是智慧的体现。
数据库设计是性能优化的基石。
合理的数据模型可以减少数据冗余、提高查询效率、确保数据一致性。
范式化
根据 MySQL 官方文档,优化的数据库设计需要平衡范式化与反范式化。
范式化设计遵循数据库设计的规范形式,通常到第三范式(3NF):
-- 范式化设计示例 CREATETABLEusers ( user_id INT PRIMARY KEY, username VARCHAR(50), email VARCHAR(100) ); CREATETABLE orders ( order_id INT PRIMARY KEY, user_id INT, order_date DATE, FOREIGNKEY (user_id) REFERENCESusers(user_id) ); CREATETABLE order_items ( item_id INT PRIMARY KEY, order_id INT, product_id INT, quantity INT, FOREIGNKEY (order_id) REFERENCES orders(order_id) );
范式化的优势在于:
- 数据冗余最小化,更新操作只需要修改一处
- 数据一致性高,减少数据异常
- 存储空间效率高
然而,过度范式化会导致查询需要频繁的 JOIN 操作,影响查询性能。
特别是在需要跨多个表检索数据时,JOIN 操作可能成为性能瓶颈。
反范式化的应用场景
当读操作远多于写操作时,适当反范式化可以显著提升查询性能:
-- 反范式化设计示例:订单表包含用户信息 CREATETABLE orders_denormalized ( order_id INT PRIMARY KEY, user_id INT, username VARCHAR(50), -- 反范式化字段 email VARCHAR(100), -- 反范式化字段 order_date DATE, total_amount DECIMAL(10, 2) ); -- 添加冗余的统计字段 CREATETABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2), stock_quantity INT, total_sold INTDEFAULT0-- 反范式化:预计算字段 );
以下流程图展示了数据库设计的决策过程,帮助你平衡范式化与反范式化:
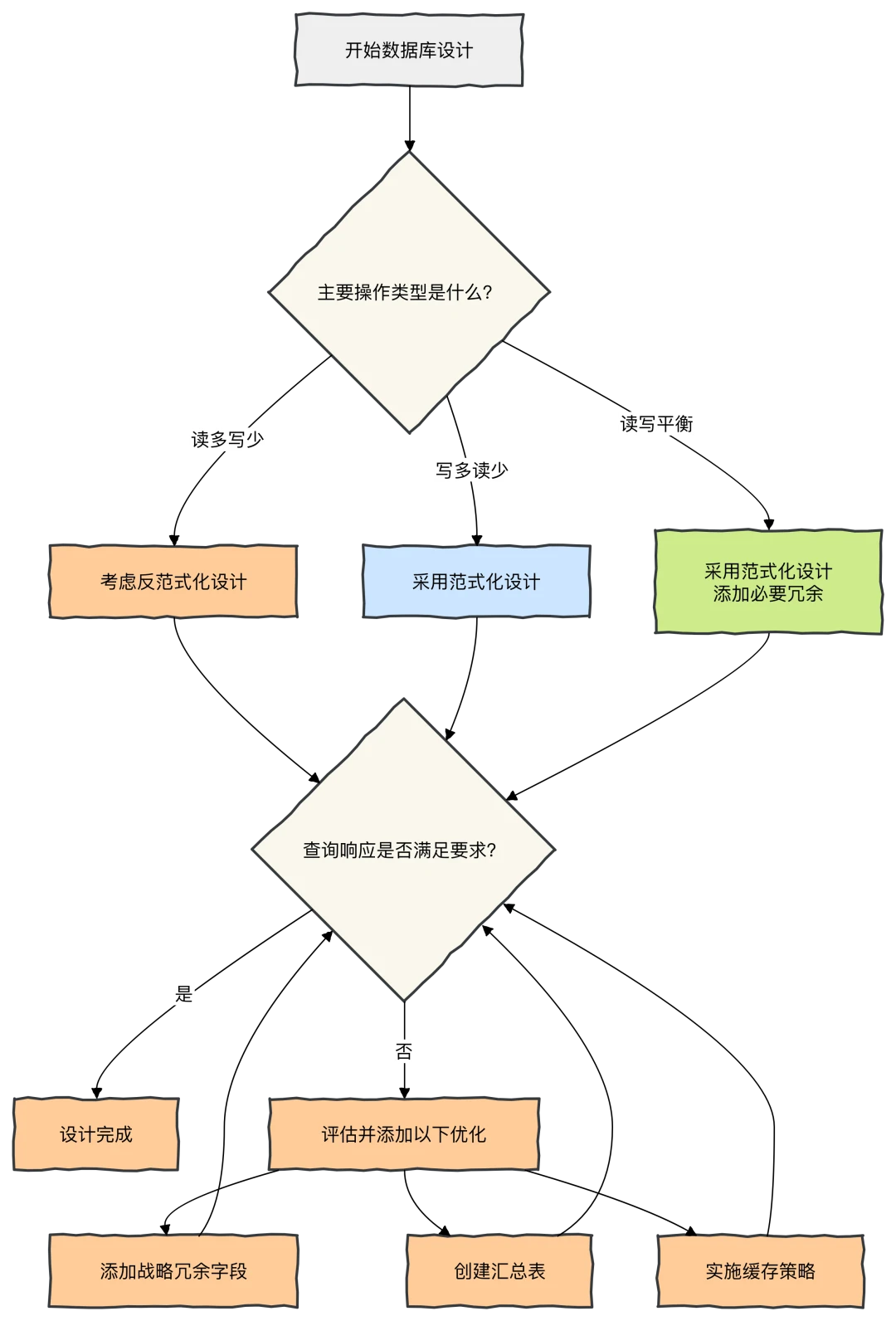
索引
没有索引的查询,就像在图书馆里找一本没编号的书——只能“全表扫描”,一本一本地翻。
索引就是书的目录,而且是超级智能的B+Tree 目录。
索引用得好,下班回家早;索引用不好,DBA 两行泪。官方第 10.3 章是索引的“百科全书”。
索引是提高查询性能的关键,但不恰当的索引反而会降低性能。MySQL 9.5 引入了新的索引类型和优化技术。
-- 创建不同类型的索引 -- 1. B-Tree 索引(默认):适用于全值匹配、范围查询、排序 CREATEINDEX idx_order_date ON orders(order_date); -- 2. 哈希索引:适用于等值查询,Memory 引擎支持 CREATEINDEX idx_hash_user ONusers(user_id) USINGHASH; -- 3. 全文索引:适用于文本搜索 CREATE FULLTEXT INDEX idx_product_desc ON products(description); -- 4. 空间索引:适用于地理空间数据 CREATE SPATIAL INDEX idx_location ON locations(coordinates); -- 5. 多列索引(复合索引) CREATEINDEX idx_user_status_date ON orders(user_id, status, order_date); -- 6. 前缀索引:为字符串列前 N 个字符创建索引 CREATEINDEX idx_email_prefix ONusers(email(20)); -- 7. 函数索引(MySQL 8.0+):为表达式结果创建索引 CREATEINDEX idx_lower_username ONusers((LOWER(username)));
B+Tree 索引是如何工作的? 码哥给你画个“武功秘籍”:
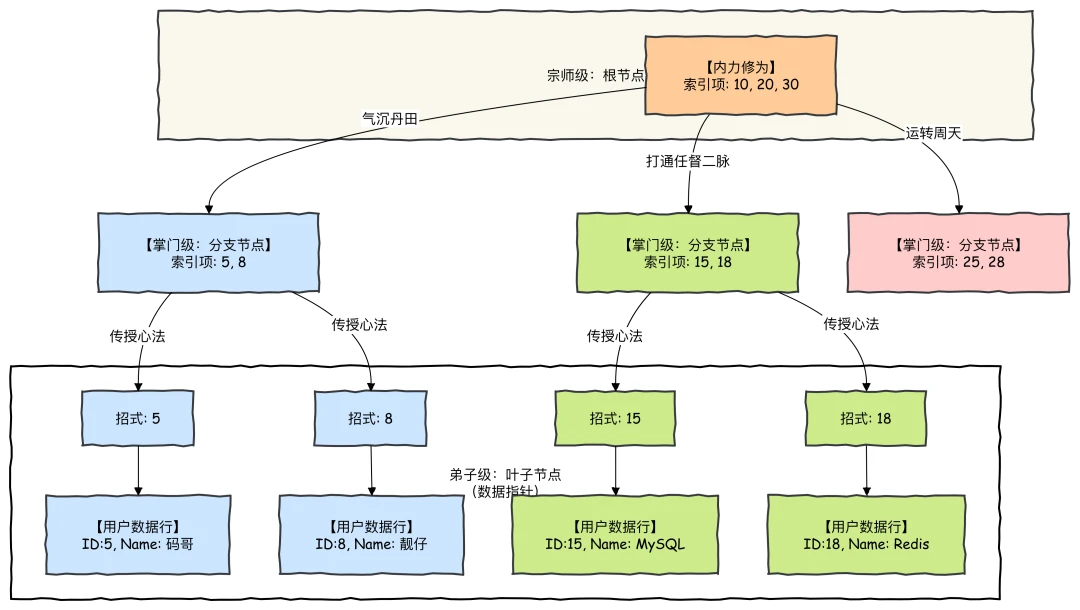
索引设计最佳实践
-- 1. 选择性高的列放在索引前面 -- user_id 的选择性高于 status,因此 user_id 在前 CREATEINDEX idx_user_status ON orders(user_id, status); -- 2. 考虑覆盖索引 -- 索引包含查询所需的所有列,避免回表 CREATEINDEX idx_covering ON orders(order_id, user_id, order_date, total_amount); -- 查询可以使用覆盖索引 SELECT order_id, user_id, order_date FROM orders WHERE user_id = 100AND order_date > '2024-01-01'; -- 3. 避免重复索引 -- 以下索引是冗余的,因为 idx_a_b 可以用于 a 列的查询 CREATEINDEX idx_a ON table1(a); -- 冗余索引 CREATEINDEX idx_a_b ON table1(a, b); -- 4. 定期分析索引使用情况 SELECT object_schema, object_name, index_name, count_star, count_read, count_fetch FROM performance_schema.table_io_waits_summary_by_index_usage WHERE index_name ISNOTNULL ORDERBY count_star DESC; -- 5. 删除未使用的索引 -- 使用 sys schema 查看索引使用统计 SELECT * FROM sys.schema_unused_indexes;
有几个点总结下:
- 最左前缀原则。你建了一个复合索引 (last_name, first_name)。这意味著:
- WHERE last_name = ‘码’索引有效
- WHERE last_name = ‘码’ AND first_name = ‘哥’ 索引有效
- WHERE first_name = ‘哥’(索引失效!)
- 别在索引列上“搞计算”
- WHERE YEAR(create_time) = 2023(❌ 索引列被函数包裹,索引卒)。
- 要写成 WHERE create_time BETWEEN ‘2023-01-01’ AND ‘2023-12-31’(✅)。
- 高选择性原则:别在“性别”这种低区分度的列上建索引。它就像问“你是中国人吗?”,大部分都是,问了也白问。要在“身份证号”这种高区分度的列上建。
当你怀疑某个索引是多余的,但又不敢删,怕删了引发线上事故怎么办?
在 MySQL 8.0+,你可以让它“隐身”:
ALTER TABLE user ADD INDEX idx_email (email); -- 创建 ALTER TABLE user ALTER INDEX idx_email INVISIBLE; -- 隐身!
索引还在,但优化器查询时完全无视它。观察一段时间,如果业务无恙,就可以放心 DROP INDEX 了。
这是线上索引管理的安全气囊!
JOIN 优化
JOIN 操作是数据库查询中最常见的性能瓶颈之一:
-- 1. 确保 JOIN 列上有索引 -- 优化前:没有索引的 JOIN SELECT * FROM orders o JOINusers u ON o.user_id = u.user_id; -- user_id 没有索引 -- 优化后:为 JOIN 列添加索引 CREATEINDEX idx_user_id ON orders(user_id); CREATEINDEX idx_user_id ONusers(user_id); -- 2. 小表驱动大表 -- 优化前:大表驱动小表 SELECT * FROM large_table l JOIN small_table s ON l.key = s.key; -- 优化后:小表驱动大表(通过 STRAIGHT_JOIN 提示) SELECTSTRAIGHT_JOIN s.*, l.* FROM small_table s JOIN large_table l ON s.key = l.key; -- 3. 避免笛卡尔积 -- 确保所有 JOIN 都有连接条件 SELECT * FROM table1, table2 WHERE table1.id = table2.table1_id; -- 正确 -- 4. 使用合适的 JOIN 类型 -- 根据数据分布选择 INNER JOIN、LEFT JOIN 等 -- 5. 分阶段 JOIN 处理大数据量 -- 第一步:获取筛选后的数据 CREATETEMPORARYTABLE filtered_orders SELECT order_id, user_id FROM orders WHERE order_date > '2024-01-01'; -- 第二步:与其他表 JOIN SELECT fo.*, u.username FROM filtered_orders fo JOINusers u ON fo.user_id = u.user_id;
排序和分组优化
你可能会遇到这种诡异情况:ORDER BY create_time DESC 明明有索引,但还是慢。
因为传统索引是升序的,反向扫描效率低。
现在可以创建真正的降序索引了:
CREATE INDEX idx_time_desc ON article (create_time DESC);
这样,你的最新文章查询就能直接顺着索引快速返回,特别适合新闻流、朋友圈时间线这种场景。
常见优化技巧如下:
-- 1. 使用索引避免排序 -- 优化前:没有索引支持排序 SELECT * FROM orders ORDERBY order_date DESC; -- 优化后:为排序字段添加索引 CREATEINDEX idx_order_date_desc ON orders(order_date DESC); -- 2. 减少排序数据量 -- 优化前:排序所有列 SELECT * FROM orders ORDERBY order_date LIMIT100; -- 优化后:只排序和选择必要列 SELECT order_id, order_date, total_amount FROM orders ORDERBY order_date LIMIT100; -- 3. 优化 GROUP BY 查询 -- 优化前:GROUP BY 没有索引 SELECT user_id, COUNT(*) FROM orders GROUPBY user_id; -- 优化后:为 GROUP BY 列添加索引 CREATEINDEX idx_user_id ON orders(user_id); -- 4. 使用派生表优化复杂分组 -- 优化前:复杂 GROUP BY SELECT o.user_id, COUNT(*) as order_count, SUM(oi.quantity) as total_quantity FROM orders o JOIN order_items oi ON o.order_id = oi.order_id GROUPBY o.user_id; -- 优化后:分阶段处理 WITH order_summary AS ( SELECT o.order_id, o.user_id, SUM(oi.quantity) as order_quantity FROM orders o JOIN order_items oi ON o.order_id = oi.order_id GROUPBY o.order_id, o.user_id ) SELECT user_id, COUNT(*) as order_count, SUM(order_quantity) as total_quantity FROM order_summary GROUPBY user_id;
分页优化
大数据量的分页查询是常见性能问题:
-- 1. 传统分页的性能问题 -- 偏移量越大,性能越差 SELECT * FROM orders ORDERBY order_date LIMIT100000, 20; -- 2. 基于游标的分页(Keyset Pagination) -- 记住最后一行的值,而不是偏移量 SELECT * FROM orders WHERE order_date > '2024-01-01' ORDERBY order_date LIMIT20; -- 下一页 SELECT * FROM orders WHERE order_date > '最后一行日期' ORDERBY order_date LIMIT20; -- 3. 使用覆盖索引优化 -- 先通过覆盖索引获取 ID,再获取数据 SELECT o.* FROM orders o JOIN ( SELECT order_id FROM orders WHERE order_date > '2024-01-01' ORDERBY order_date LIMIT100000, 20 ) tmp ON o.order_id = tmp.order_id; -- 4. 分区表分页优化 -- 使用分区减少扫描范围 SELECT * FROM orders PARTITION (p2024_q1) ORDERBY order_date LIMIT100000, 20;
索引失效的 10 大场景
索引失效是慢查询的主要原因之一,开发中一定要避免以下 10 种场景:
- 使用 SELECT:查询所有字段,无法使用覆盖索引,必须回表查询,同时增加数据传输量;
- 索引列使用函数 / 运算:比如
WHERE DATE(create_time) = '2025-01-01'、WHERE age+1=20,MySQL 无法使用索引; - 隐式类型转换:比如索引字段是 INT 类型,查询时用字符串 WHERE age=’20’,MySQL 会进行类型转换,索引失效;
- 使用 LIKE % xxx:左模糊查询
WHERE name like '%张三'会导致索引失效,右模糊WHERE name like '张三%'索引生效; - 使用 OR 连接条件:OR 两边的字段如果有一个没有索引,整个查询的索引都会失效;
- 使用 NOT IN/NOT EXISTS:这两个操作会导致 MySQL 放弃索引,选择全表扫描;
- 联合索引违反最左匹配原则:如上文所述,跳过左侧字段、范围查询在中间都会导致索引失效;
- 数据量太小:表中数据量过少时,MySQL 优化器会认为全表扫描比使用索引更快,主动放弃索引;
- 索引列有 NULL 值:MySQL 对 NULL 值的处理特殊,若索引列大量为 NULL,索引效率会大幅降低,建议设置默认值;
- 过度索引:表中索引过多,MySQL 优化器在选择索引时会花费大量时间,甚至选择错误的索引。
查询分析与优化策略
任何优化后,都要用 EXPLAIN 看看 SQL 的“体检报告”。关注 type 字段(最好达到 ref 或 range)、key 字段(是否用了你想用的索引)、rows 字段(扫描行数越少越好)。
很多人以为优化就是调参数,大错特错!80%的性能问题源于糟糕的 SQL。
MySQL 9.5 提供了强大的查询分析工具,帮助我们识别和解决性能瓶颈。
EXPLAIN 命令深度解析
任何不跑 EXPLAIN 的优化都是耍流氓!这玩意儿就是 SQL 的“体检报告”。
-- 使用 EXPLAIN 分析查询 EXPLAINFORMAT=JSON SELECT o.order_id, o.order_date, u.username, SUM(oi.quantity * p.price) as total_amount FROM orders o JOINusers u ON o.user_id = u.user_id JOIN order_items oi ON o.order_id = oi.order_id JOIN products p ON oi.product_id = p.product_id WHERE o.order_date >= '2024-01-01' GROUPBY o.order_id HAVING total_amount > 1000 ORDERBY o.order_date DESC LIMIT10;
你得会看这几个关键指标:
id:查询标识符,相同 id 表示是同一查询块.select_type:查询类型(SIMPLE、PRIMARY、SUBQUERY 等)table:访问的表partitions:匹配的分区type列:这是“访问类型”,从好到坏大概是:system> const> eq_ref> ref> range> index> ALL。如果看到 ALL(全表扫描),恭喜你,索引大概率没用好。key列:告诉你实际用了哪个索引。如果为 NULL,呵呵,索引失踪了。possible_keys:可能使用的索引key_len:使用的索引长度ref:与索引比较的列rows列:表示 MySQL 认为它需要检查多少行。这个数字越大,查询越累。filtered:按条件过滤的行百分比Extra列:这里的信息极度重要!比如出现 Using filesort(需要额外的排序)或 Using temporary(需要创建临时表),都是性能杀手。
码哥骚操作:用EXPLAIN FORMAT=JSON获取更详尽的“深度体检报告”,里面连成本(cost)都算给你看!
子查询的“陷阱”与“救赎”
很多靓仔写子查询是这样的:
SELECT * FROM users WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);
看着没问题?但 MySQL 可能把它变成一个可怕的“相关子查询”,对外层每一行都执行一次子查询,慢到怀疑人生。
官方推荐救赎方案:使用JOIN或EXISTS
SELECT u.* FROM users u WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.amount > 100); -- 或者更直接的 JOIN SELECT DISTINCT u.* FROM users u INNER JOIN orders o ON u.id = o.user_id WHERE o.amount > 100;
以下是一些常见技巧。
-- 1. 避免使用 SELECT *,只选择需要的列 -- 优化前 SELECT * FROMusersWHERE user_id = 100; -- 优化后 SELECT user_id, username, email FROMusersWHERE user_id = 100; -- 2. 使用 EXISTS 代替 IN(当子查询返回大量数据时) -- 优化前 SELECT * FROM orders WHERE user_id IN (SELECT user_id FROMusersWHEREstatus = 'active'); -- 优化后 SELECT * FROM orders o WHEREEXISTS (SELECT1FROMusers u WHERE u.user_id = o.user_id AND u.status = 'active'); -- 3. 将复杂查询拆分为多个简单查询 -- 优化前:一个复杂的多表 JOIN 查询 -- 优化后:拆分为多个查询,在应用层组合数据 -- 4. 合理使用 LIMIT -- 优化前:不必要的大量数据检索 SELECT * FROM orders WHERE order_date > '2024-01-01'; -- 优化后:添加 LIMIT 限制 SELECT * FROM orders WHERE order_date > '2024-01-01'LIMIT100; -- 5. 避免在 WHERE 子句中对列进行函数操作 -- 优化前 SELECT * FROM orders WHEREYEAR(order_date) = 2024; -- 优化后 SELECT * FROM orders WHERE order_date >= '2024-01-01'AND order_date < '2025-01-01';
MySQL 9.5 系统级优化
作为默认引擎,InnoDB 的调优是重中之重。
缓冲池(Buffer Pool)
这是 InnoDB 的灵魂所在。innodb_buffer_pool_size必须调大,通常是**系统总内存的 70%-80%**。
一个足够大的 BP 能让热数据常驻内存,告别磁盘 I/O。
“但怎么知道 BP 是否够用?看状态:
SHOW STATUS LIKE ‘innodb_buffer_pool_read%’;
如果 Innodb_buffer_pool_reads(从磁盘读取的页数)远大于Innodb_buffer_pool_read_requests(总的读请求),说明 BP 太小了,很多数据不得不去磁盘读。
日志系统
Redo Log 是 InnoDB 的“日记本”,为保证事务持久性而存在。innodb_flush_log_at_trx_commit这个参数是性能和安全的关键平衡点:
- =1(默认):每次提交都刷盘。最安全,但最慢。适用于金融、交易等对数据一致性要求极高的场景。
- =2:每次提交只写到操作系统缓存,每秒刷一次盘。性能好,崩溃可能丢失 1 秒数据。适用于大多数业务场景。
- =0:每秒写和刷盘。性能最好,但崩溃可能丢失最多 1 秒数据。适用于可容忍少量数据丢失的场景(如日志收集)。
码哥建议:如果不是强一致性要求,尝试设置为 2,性能提升会非常明显。
最后给出一份常用的配置。
MySQL 9.5 引入了新的配置参数,优化默认值:
# InnoDB 缓冲池配置(通常设置为系统内存的 70-80%) innodb_buffer_pool_size = 16G innodb_buffer_pool_instances = 8 # 减少争用,通常设为 CPU 核心数 # 日志文件配置 innodb_log_file_size = 2G # 更大的日志文件减少检查点 innodb_log_buffer_size = 64M # 日志缓冲区大小 # 连接管理 max_connections = 500 # 根据应用需求调整 thread_cache_size = 100 # 线程缓存大小 # 查询缓存(MySQL 8.0+已移除,注意替代方案) # 使用应用层缓存或 ProxySQL 查询缓存 # 临时表和排序优化 tmp_table_size = 256M # 内存临时表最大大小 max_heap_table_size = 256M # 内存表最大大小 sort_buffer_size = 4M # 排序缓冲区大小 # InnoDB I/O 优化 innodb_flush_method = O_DIRECT # Linux 系统推荐 innodb_io_capacity = 2000 # 根据磁盘性能调整 innodb_io_capacity_max = 4000 # 最大 I/O 容量 # 事务隔离与锁 transaction_isolation = READ-COMMITTED # 大多数应用推荐 innodb_lock_wait_timeout = 50 # 锁等待超时时间
监控与度量——没有度量,就没有优化
MySQL 9.5 增强了监控和诊断功能,优化不是玄学,要靠数据说话。
-- 1. 使用 Performance Schema 监控性能 -- 查看最耗时的 SQL 语句 SELECT DIGEST_TEXT, COUNT_STAR, SUM_TIMER_WAIT/1000000000as total_sec, AVG_TIMER_WAIT/1000000000as avg_sec, MAX_TIMER_WAIT/1000000000as max_sec FROM performance_schema.events_statements_summary_by_digest ORDERBY SUM_TIMER_WAIT DESC LIMIT10; -- 2. 使用 sys schema 快速诊断 -- 查看锁等待情况 SELECT * FROM sys.innodb_lock_waits; -- 查看未使用索引 SELECT * FROM sys.schema_unused_indexes; -- 查看表统计信息 SELECT * FROM sys.schema_table_statistics; -- 3. 使用慢查询日志 -- 启用慢查询日志 SETGLOBAL slow_query_log = ON; SETGLOBAL long_query_time = 1; # 超过 1 秒的查询 -- 分析慢查询日志 # 使用 mysqldumpslow 工具 mysqldumpslow -s t /var/log/mysql/mysql-slow.log # 使用 pt-query-digest 工具 pt-query-digest /var/log/mysql/mysql-slow.log -- 4. 实时监控 -- 查看当前连接和执行语句 SELECT * FROM information_schema.processlist WHERE COMMAND != 'Sleep' ORDERBYTIMEDESC; -- 查看 InnoDB 状态 SHOWENGINEINNODBSTATUS; -- 5. 使用 MySQL Shell 性能报告 -- MySQL Shell 提供了高级诊断功能 \sql \performance report
- 慢查询日志(Slow Query Log):你的“病历本”。开启它,记录下所有执行超过 long_query_time(比如 0.1 秒)的 SQL。
- Performance Schema:MySQL 的“实时监控大屏”。它能深入监控到每个语句的执行阶段、锁等待、I/O 操作,是进阶优化的不二法门。
- sys Schema:基于 Performance Schema 的“可视化报表库”。提供人类可读的视图,比如直接查询哪些语句全表扫描了:
SELECT * FROM sys.statements_with_full_table_scans;
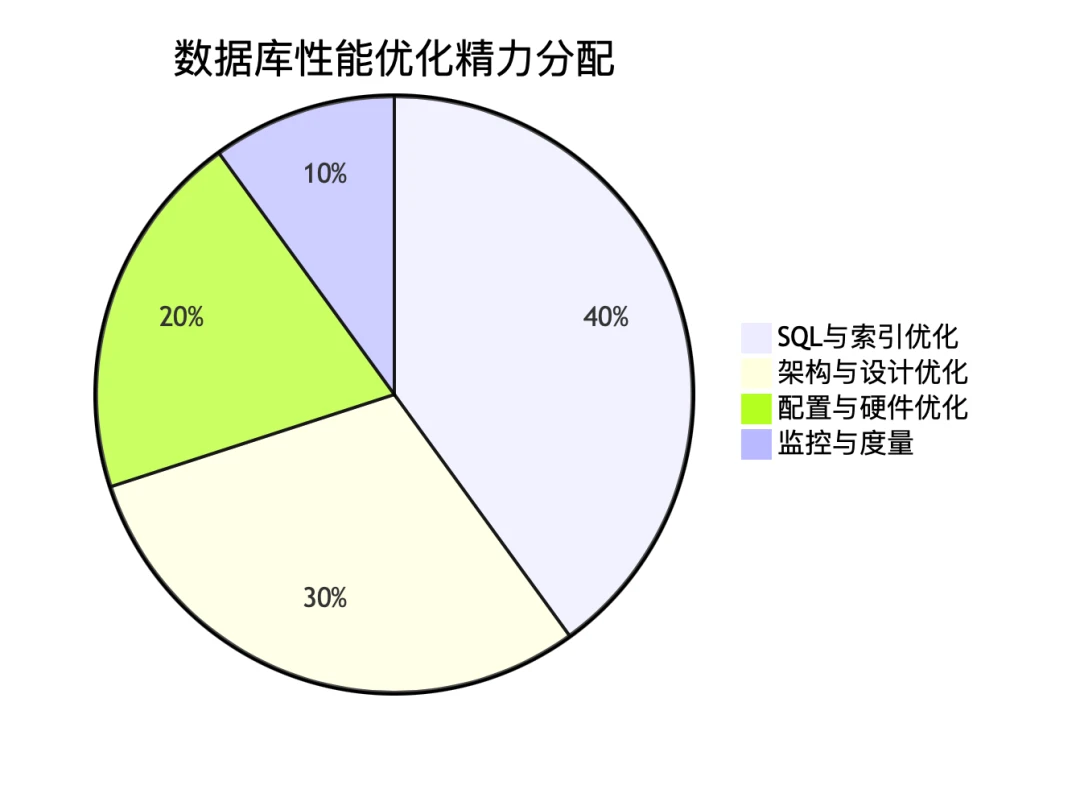
总结:MySQL 优化心法秘籍
- 先诊断,后开药:EXPLAIN、慢查询日志、Performance Schema 是你的“听诊器”和“CT 机”。
- SQL 为王:90%的性能问题能从 SQL 和索引层面解决或缓解。掌握哈希连接、子查询优化。
- 理解 InnoDB:调好 Buffer Pool 和 Redo Log,你就掌握了 InnoDB 的命脉。
- 善用新特性:不可见索引、降序索引等是线上运维和性能提升的利器。
- 硬件是保障:SSD 是解决 I/O 瓶颈的银弹,内存是缓解 I/O 压力的黄金。
- 数据驱动决策:建立监控基线,任何优化前后都要对比数据,确保真的有效。
优化是一条永无止境的路,但跟着 MySQL 官方文档和码哥的这份指南,你一定能从“新手村”勇者,成长为独当一面的“性能调优大师”!
文章来源公众号:码哥跳动
以上关于MySQL 9.5 性能优化终极指南:从 10s 到 10ms 的 5 个核心心法的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » MySQL 9.5 性能优化终极指南:从 10s 到 10ms 的 5 个核心心法