
性能超越LLaMA2-7B!AI模型JetMoE-8B训练成本不到10万美元
AI 概述
JetMoE-8B 是一款采用稀疏激活架构的人工智能模型,其性能卓越且训练成本不到 10 万美元,令人惊讶的是,它的表现甚至超越了 LLaMA2-7B、LLaMA-13B 和 DeepseekMoE-16B。
JetMoE-8B 由 24 个块组成,每个块包含两个 MoE 层:注意力头混合(MoA)和 MLP 专家混合(MoE)。每个 MoA 和 MoE 层有 8 个专家,并且每个输入令牌...
JetMoE-8B 是一款采用稀疏激活架构的人工智能模型,其性能卓越且训练成本不到 10 万美元,令人惊讶的是,它的表现甚至超越了 LLaMA2-7B、LLaMA-13B 和 DeepseekMoE-16B。
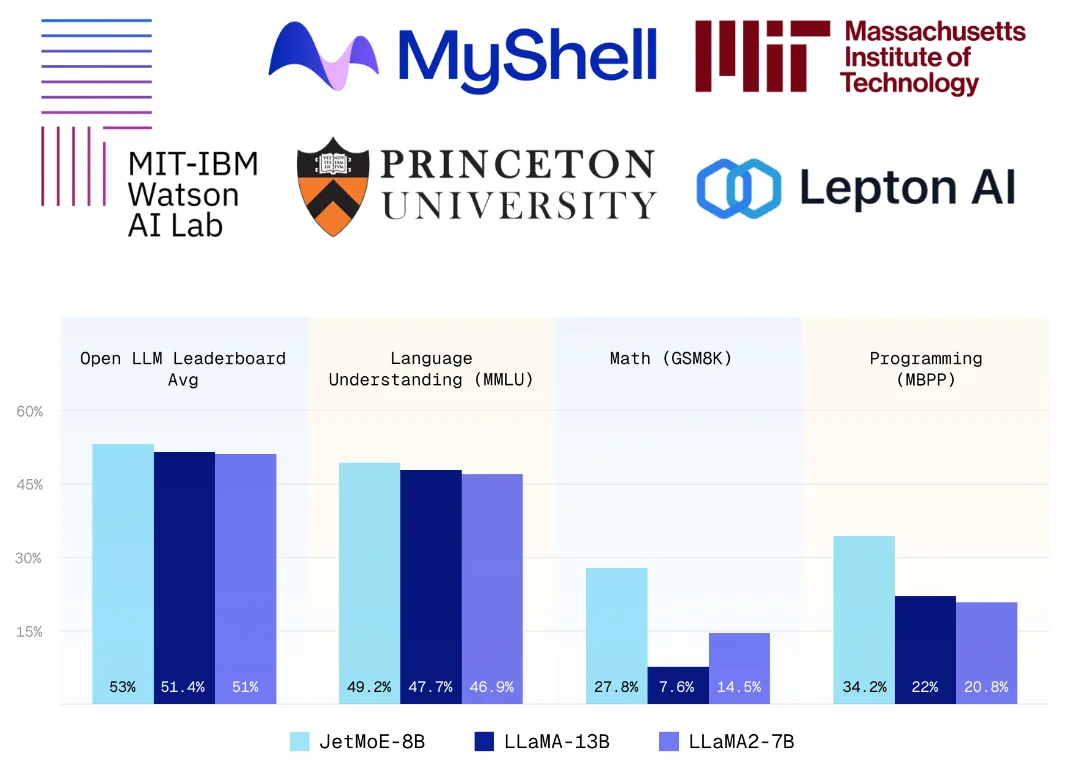
JetMoE-8B 由 24 个块组成,每个块包含两个 MoE 层:注意力头混合(MoA)和 MLP 专家混合(MoE)。每个 MoA 和 MoE 层有 8 个专家,并且每个输入令牌激活 2 个专家。这种独特的设计使得在不牺牲性能的情况下显著降低了计算成本。
值得一提的是,尽管 JetMoE-8B 的总参数量达到 80 亿,但由于其特殊的架构设计,每个输入令牌仅激活约 22 亿参数,从而大大减少了总体的计算需求。
此外,JetMoE-8B 的训练完全依赖于公开数据,并且整个训练过程,包括代码,都是完全开源的,这无疑为 AI 领域的研究和应用提供了极大的便利。
在与 Open LLM 排行榜相同的评估方法下,JetMoE-8B 的性能表现优于 LLaMA2-7B、LLaMA-13B 和 DeepseekMoE-16B,这一结果无疑是对其高效性能的最好证明。
与此同时,与具有类似训练和推理计算的模型(如 Gemma-2B)相比,JetMoE-8B 展示了更优异的表现。这不仅证明了其在性能上的优势,也展示了其在成本效益上的显著优势。
模型地址:点击这里
以上关于性能超越LLaMA2-7B!AI模型JetMoE-8B训练成本不到10万美元的文章就介绍到这了,更多相关内容请搜索码云笔记以前的文章或继续浏览下面的相关文章,希望大家以后多多支持码云笔记。
 微信
微信 支付宝
支付宝声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 性能超越LLaMA2-7B!AI模型JetMoE-8B训练成本不到10万美元
如若内容造成侵权/违法违规/事实不符,请将相关资料发送至 admin@mybj123.com 进行投诉反馈,一经查实,立即处理!
重要:如软件存在付费、会员、充值等,均属软件开发者或所属公司行为,与本站无关,网友需自行判断
码云笔记 » 性能超越LLaMA2-7B!AI模型JetMoE-8B训练成本不到10万美元







